1、API资源对象Pod 在K8s里,YAML用来声明API对象的,那么API对象都有哪些?可以这样查看资源对象:
Pod为K8s里最小、最简单的资源对象。
运行一个pod
1 $ kubectl run pod-demo --image=busybox
从已知Pod导出YAML文件:
1 $ kubectl get pod pod-demo -o yaml > pod-demo.yaml
Pod YAML示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 $ vi ngx-pod.yaml apiVersion: v1 kind: Pod metadata: name: ngx-pod namespace: aming labels: env: dev spec: containers: - image: nginx:1.23.2 imagePullPolicy: IfNotPresent name: ngx env: - name: os value: "Rocky Linux" ports: - containerPort: 80
使用YAML创建pod:
1 $ kubectl apply -f ngx-pod.yaml
删除pod:
1 $ kubectl delete -f ngx-pod.yaml
1.1 Pod原理 Pod 是在 K8s集群中运行部署应用或服务的最小单元。
在同一个Pod中其实可以同时运行多个容器,这些容器能够共享网络、存储以及 CPU/内存等资源。
网络命名空间共享:pause容器为整个Pod创建一个网络命名空间,Pod内的其他容器都将加入这个网络命名空间。这样,Pod中的所有容器都可以共享同一个IP地址和端口空间,从而实现容器间的紧密通信。
PID命名空间共享:pause容器充当Pod内其他容器的父容器,它们共享同一个PID命名空间。这使得Pod内的容器可以通过进程ID直接发现和相互通信,同时也使得Pod具有一个统一的生命周期。
生命周期管理:pause容器作为Pod中其他容器的父容器,负责协调和管理它们的生命周期。当pause容器启动时,它会成为Pod中其他容器的根容器。当pause容器终止时,所有其他容器也会被自动终止,确保了整个Pod的生命周期的一致性。
保持Pod状态:pause容器保持运行状态,即使Pod中的其他容器暂时停止或崩溃,也可以确保Pod保持活跃。这有助于Kubernetes更准确地监视和管理Pod的状态。
1.2 Pod生命周期 Pod生命周期包括以下几个阶段:
Pending:在此阶段,Pod已被创建,但尚未调度到运行节点上。此时,Pod可能还在等待被调度,或者因为某些限制(如资源不足)而无法立即调度。
Running:在此阶段,Pod已被调度到一个节点,并创建了所有的容器。至少有一个容器正在运行,或者正在启动或重启。
Succeeded:在此阶段,Pod中的所有容器都已成功终止,并且不会再次重启。
Failed:在此阶段,Pod中的至少一个容器已经失败(退出码非零)。这意味着容器已经崩溃或以其他方式出错。
Unknown:在此阶段,Pod的状态无法由Kubernetes确定。这通常是因为与Pod所在节点的通信出现问题。
除了这些基本的生命周期阶段之外,还有一些更详细的容器状态,用于描述容器在Pod生命周期中的不同阶段:
ContainerCreating:容器正在创建,但尚未启动。
Terminating:容器正在终止,但尚未完成。
Terminated:容器已终止。
Waiting:容器处于等待状态,可能是因为它正在等待其他容器启动,或者因为它正在等待资源可用。
Completed:有一种Pod是一次性的,不需要一直运行,只要执行完就会是此状态。
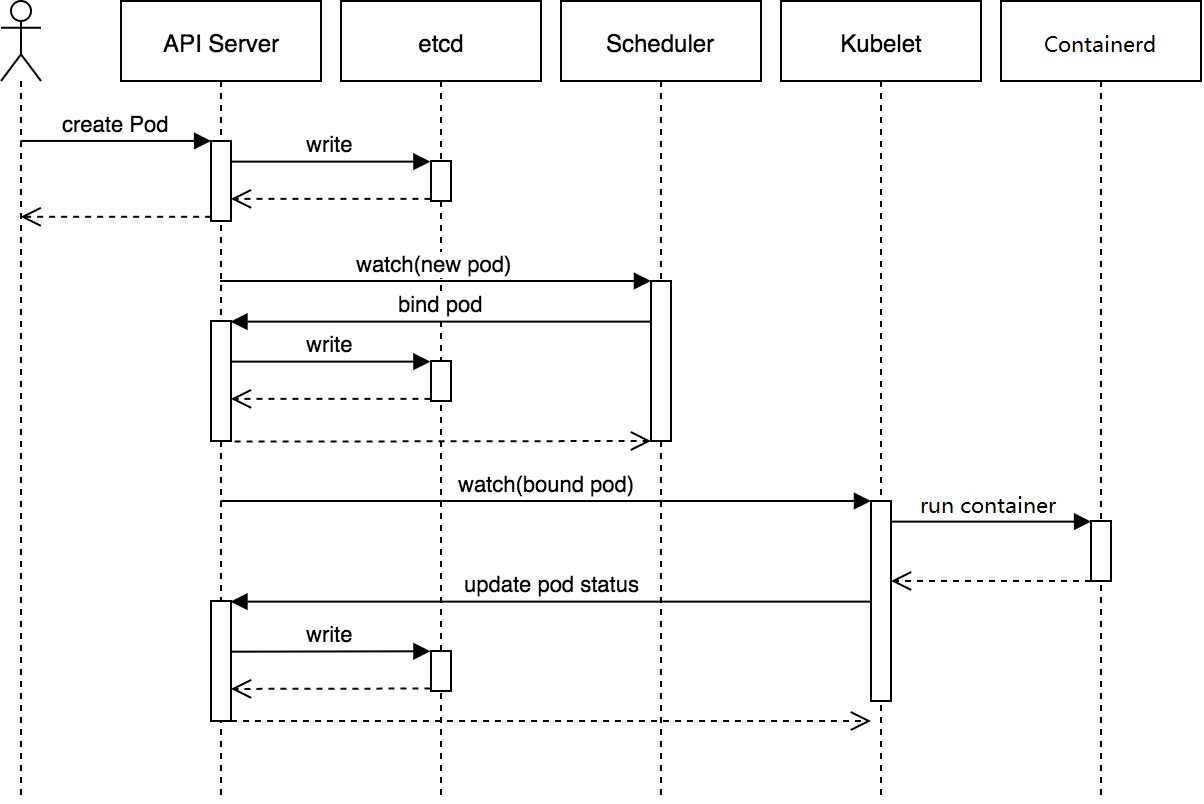
1.3 创建Pod流程
1 2 3 4 5 6 7 8 9 10 1. 用户通过kubectl或其他API客户端提交Pod对象给API server。2. API server尝试将Pod对象的相关信息存入etcd中,写入操作完成后API server会返回确认信息至客户端。3. API server开始反映etcd中的状态变化。4. 所有的Kubernetes组件均使用watch机制来跟踪检查API server上的相关变化。5. Kube-scheduler通过其watcher观察到API server创建了新的Pod对象但尚未绑定至任何节点。6. Kube-scheduler为Pod对象挑选一个工作节点并将结果更新至API server。7. 调度结果由API server更新至etcd,而且API server也开始反映此Pod对象的调度结果。8. Pod 被调度的目标工作节点上的kubelet尝试在当前节点上调用Containerd启动容器,并将容器的结果状态返回至API server。9. API server将Pod 状态信息存入etcd。10. 在etcd确认写操作完成后,API server将确认信息发送至相关的kubelet。
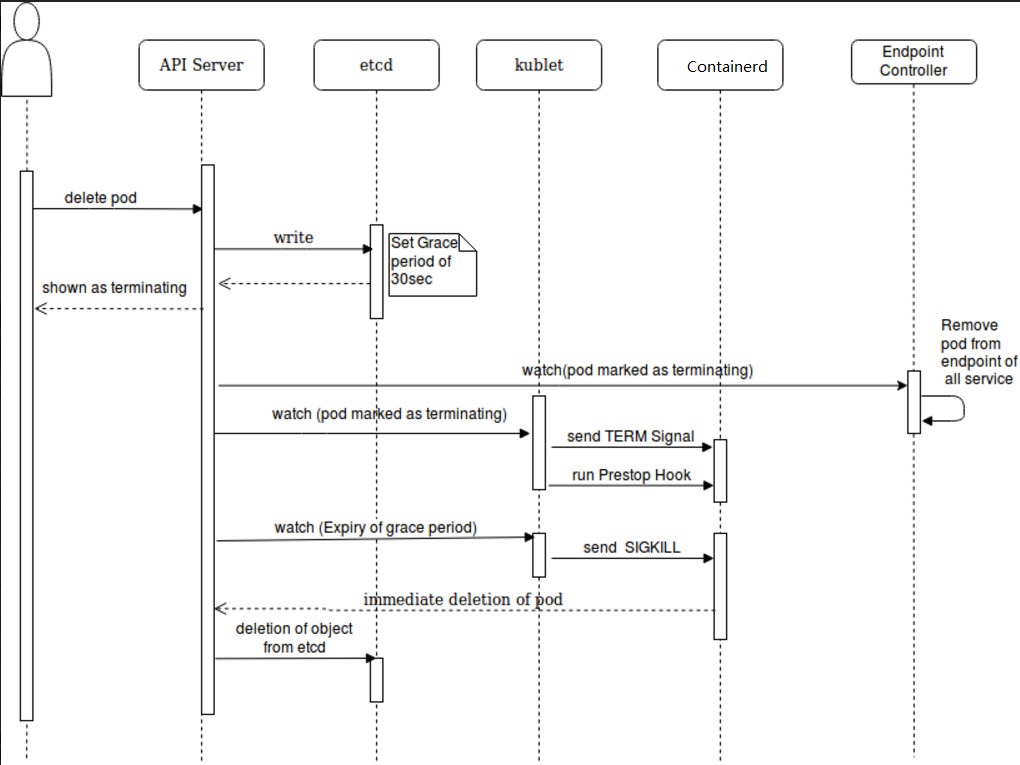
1.4 删除Pod流程
1 2 3 4 5 6 7 8 1. 请求删除Pod。2. API server将Pod标记为Terminating状态。3. (与第 2 步同时进行)kubelet在监控到Pod对象转为Terminating状态的同时启动Pod关闭过程。4. (与第 2 步同时进行)Service将Endpoint摘除。5. 如果当前Pod对象定义了preStop hook,则在其标记为Terminating后会以同步的方式执行,宽限期开始计时。6. Pod中的容器进程收到TERM信号。7. 宽限期结束后,若进程仍在运行,会收到SIGKILL信号。8. kubelet请求API server将此Pod对象的宽限期设置为0,从而完成删除操作。
2、Pod资源限制 2.1 Resource Quota 资源配额Resource Quotas(简称quota)是对namespace进行资源配额,限制资源使用的一种策略。
可限定资源类型:limits.cpu、requests.cpu、limits.memory、requests.memoryrequests.storage:存储资源总量,如500Gipersistentvolumeclaims:pvc的个数
limits:最多可以使用多少requests:最少需要分配多少
对象数,即可创建的对象的个数pods, replicationcontrollers, configmaps, secrets,persistentvolumeclaims,services, services.loadbalancers,services.nodeports
注意:
Resource Quota示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 $ cat > quota.yaml <<EOF apiVersion: v1 kind: ResourceQuota metadata: namespace: aming name: aming-quota spec: hard: pods: 50 requests.cpu: 0.5 requests.memory: 512Mi limits.cpu: 5 limits.memory: 16Gi configmaps: 20 persistentvolumeclaims: 20 replicationcontrollers: 20 secrets: 20 services: 50 EOF
生效
1 $ kubectl apply -f quota.yaml
查看
1 $ kubectl get quota -n aming
测试:
命令行创建deployment,指定Pod副本为7
1 $ kubectl create deployment testdp --image=nginx:1.23.2 -n aming --replicas=7
查看deployment和pod
1 $ kubectl get deploy,po -n aming
2.2 Pod的limits和requests Resource Quota是针对namespace下面所有的Pod的限制,而Pod自身也有限制。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 $ cat > quota-pod.yaml <<EOF apiVersion: v1 kind: Pod metadata: name: quota-pod namespace: aming spec: containers: - image: nginx:1.23.2 name: ngx imagePullPolicy: IfNotPresent ports: - containerPort: 80 resources: limits: cpu: 0.5 memory: 2Gi requests: cpu: 200m memory: 512Mi EOF
3、API资源对象Deployment Deployment是Kubernetes1.2引入的新概念,引入的目的是为了更好的解决Pod的编排问题,为此Deployment内部使用了Replica Set 来实现目的
Deployment 相对于RC的一个最大升级是我们可以随时知道当前Pod”部署”的进度,实际上由于一个Pod的创建、调度、绑定节点及在Node上启动对应的容器这一完整过程需要一定的时间,所以我们期待系统启动N个Pod副本的目标状态,实际上是一个连续变化的”部署过程”导致的最终状态
Deployment经典常用场景
1.创建一个Deployment对象来生成对应的Replica Set并完成Pod副本的创建过程
2.检查Deployment的状态来看部署动作是否完成(Pod副本的数量是否达到预期的值)
3.更新Deployment以创建新的Pod (比如镜像升级)
4.如果当前Deployment不稳定,则回滚到一个早先的Deployment版本
5.暂停Deployment以便于一次性修改多个PodTemplateSpec的配置项,之后再恢复Deployment,进行新的发布
6.扩展Deployment以应对高负载
7.查看Deployment的状态,以此作为发布是否成功的指标。
8.清理不再需要的旧版本ReplicaSets
Deployment YAML示例:
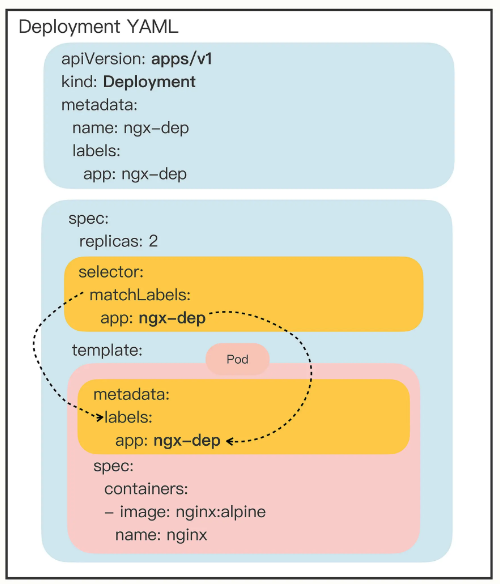
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 $ vi ng-deploy.yaml apiVersion: apps/v1 kind: Deployment metadata: labels: app: myng name: ng-deploy spec: replicas: 2 selector: matchLabels: app: myng template: metadata: labels: app: myng spec: containers: - name: myng image: nginx:1.23.2 ports: - name: myng-port containerPort: 80
在 Kubernetes(K8s)中,matchLabels 和 labels 都是用于筛选和管理 Kubernetes 资源的关键概念。它们之间的关系可以通过以下几点来解释:
定义:
作用:
labels:用于区分和识别不同的资源,方便您在集群中管理和组织资源。例如,您可以为不同的应用程序分配不同的标签,以便轻松识别它们。matchLabels:用于定义资源筛选条件,以便在基于标签的策略中应用规则。例如,您可以使用 matchLabels 来匹配具有特定标签的 Pod,以便执行滚动更新或实现蓝绿部署。
matchLabels和labels之间的关系:
假设您有两个 Pod,一个用于运行应用程序 A,另一个用于运行应用程序 B。您可以为这两个 Pod 分配不同的标签:
1 2 3 4 5 6 7 - Pod A: labels: app: A - Pod B: labels: app: B
现在,您可以使用 matchLabels 来根据标签过滤这两个 Pod:
这将匹配具有 “app: A” 标签的 Pod A,而不匹配具有 “app: B” 标签的 Pod B。
总之,matchLabels 和 labels 在 Kubernetes 中共同作用,帮助您根据标签筛选和管理资源。labels 用于为资源分配标识,而 matchLabels 用于根据这些标识执行特定操作。
使用YAML创建deploy:
1 $ kubectl apply -f ng-deploy.yaml
查看:
1 2 $ kubectl get deploy
4、API资源对象Service
Service是Kubernetes里最核心 的资源对象之一,Service定义了一个服务的访问入口地址,前端的应用(Pod)通过这个入口地址访问其背后的一组由Pod副本组成的集群实力。 Service与其后端Pod副本集群之间则是通过Label Selector来实现”无缝对接 “。而RC的作用实际上是保证Service 的服务能力和服务质量处于预期的标准。
Service简称(svc) YAML示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 $ vi ng-svc.yaml apiVersion: v1 kind: Service metadata: name: ngx-svc spec: selector: app: myng ports: - protocol: TCP port: 80 targetPort: 80
使用YAML创建service:
1 $ kubectl apply -f ng-svc.yaml
查看:
1 2 3 4 $ kubectl get svc
三种Service 类型:1)ClusterIP
1 2 3 4 5 6 7 8 spec: selector: app: myng type: ClusterIP ports: - protocol: TCP port: 8080 targetPort: 80
2)NodePort
1 2 3 4 5 6 7 8 9 spec: selector: app: myng type: NodePort ports: - protocol: TCP port: 8080 targetPort: 80 nodePort: 30009
3)LoadBlancer
1 2 3 4 5 6 7 8 spec: selector: app: myng type: LoadBlancer ports: - protocol: TCP port: 8080 targetPort: 80
5、API资源对象DaemonSet 有些场景需要在每一个node上运行Pod(比如,网络插件calico、监控、日志收集),Deployment无法做到,而Daemonset(简称ds)可以。Deamonset的目标是,在集群的每一个节点上运行且只运行一个Pod。
适用场景
集群存储守护程序,如glusterd、ceph要部署在每个节点上提供持久性存储
节点监视守护进程,如prometheus监控集群,可以在每个节点上运行一个node-exporter进程来收集监控节点的信息
日志收集守护程序,如fluentd或logstash,在每个节点运行容器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 $ vi ds-demo.yaml apiVersion: apps/v1 kind: DaemonSet metadata: labels: app: ds-demo name: ds-demo spec: selector: matchLabels: app: ds-demo template: metadata: labels: app: ds-demo spec: containers: - name: ds-demo image: nginx:1.23.2 ports: - name: mysql-port containerPort: 80
使用YAML创建ds
1 $ kubectl apply -f ds-demo.yaml
查看:
1 2 $ kubectl get ds
但只在两个node节点上启动了pod,没有在master上启动,这是因为默认master有限制。
1 2 $ kubectl describe node k8s01 |grep -i 'taint'
说明:Taint叫做污点,如果某一个节点上有污点,则不会被调度运行pod。
但是这个还得取决于Pod自己的一个属性:toleration(容忍),即这个Pod是否能够容忍目标节点是否有污点。
为了解决此问题,我们可以在Pod上增加toleration属性。下面改一下YAML配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 $ vi ds-demo.yaml apiVersion: apps/v1 kind: DaemonSet metadata: labels: app: ds-demo name: ds-demo spec: selector: matchLabels: app: ds-demo template: metadata: labels: app: ds-demo spec: tolerations: - key: node-role.kubernetes.io/control-plane effect: NoSchedule containers: - name: ds-demo image: nginx:1.23.2 ports: - name: mysql-port containerPort: 80
再次应用此YAML
1 $ kubectl apply -f ds-demo.yaml
6、API资源对象StatefulSet Pod根据是否有数据存储分为有状态和无状态:
无状态:指的Pod运行期间不会产生重要数据,即使有数据产生,这些数据丢失了也不影响整个应用。比如Nginx、Tomcat等应用适合无状态。
有状态:指的是Pod运行期间会产生重要的数据,这些数据必须要做持久化,比如MySQL、Redis、RabbitMQ等。
Deployment和Daemonset适合做无状态,而有状态也有一个对应的资源,那就是Statefulset(简称sts)。
StatefulSet是为了解决有状态服务的问题(对应Deployment 和Replica Set 是为无状态服务而设计),其应用场景包括:
稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于PVC来实现
稳定的网络标志,即Pod重新调度后其PodName和HostName不变,基于Headless Service(即没有Cluster IP的Service)来实现
有序部署,有序扩展,即Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依次进行(即从0到N-1,在下一个Pod运行之前所有之前的Pod必须都是Running和Ready状态),基于init containers来实现
有序收缩,有序删除(即从N-1到0)
说明:由于StatefulSet涉及到了数据持久化,用到了StorageClass,需要先创建一个基于NFS的StorageClass
额外开一台虚拟机,搭建NFS服务(具体步骤略)
另外,要想使用NFS的sc,还需要安装一个NFS provisioner,它的作用是自动创建NFS的pvhttps://github.com/kubernetes-sigs/nfs-subdir-external-provisioner
将源码下载下来:
1 $ git clone https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner
1 2 3 $ cd nfs-subdir-external-provisioner/deploy's/namespace: default/namespace: kube-system/' rbac.yaml
修改deployment.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 $ sed -i 's/namespace: default/namespace: kube-system/' deployment.yaml spec: serviceAccountName: nfs-client-provisioner containers: - name: nfs-client-provisioner image: chronolaw/nfs-subdir-external-provisioner:v4.0.2 volumeMounts: - name: nfs-client-root mountPath: /persistentvolumes env: - name: PROVISIONER_NAME value: k8s-sigs.io/nfs-subdir-external-provisioner - name: NFS_SERVER value: 192.168 .222 .128 - name: NFS_PATH value: /data/nfs volumes: - name: nfs-client-root nfs: server: 192.168 .222 .128 path: /data/nfs
应用yaml
1 2 $ kubectl apply -f deployment.yaml
SC YAML示例
1 2 3 4 5 6 7 8 9 $ cat class.yaml apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: nfs-client provisioner: k8s-sigs.io/nfs-subdir-external-provisioner parameters: archiveOnDelete: "false"
Sts示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 $ vi redis-sts.yaml apiVersion: apps/v1 kind: StatefulSet metadata: name: redis-sts spec: serviceName: redis-svc volumeClaimTemplates: - metadata: name: redis-pvc spec: storageClassName: nfs-client accessModes: - ReadWriteMany resources: requests: storage: 500Mi replicas: 2 selector: matchLabels: app: redis-sts template: metadata: labels: app: redis-sts spec: containers: - image: redis:6.2 name: redis ports: - containerPort: 6379 volumeMounts: - name: redis-pvc mountPath: /data
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 $ vi redis-svc.yaml apiVersion: v1 kind: Service metadata: name: redis-svc spec: selector: app: redis-sts ports: - port: 6379 protocol: TCP targetPort: 6379
应用两个YAML文件
1 $ kubectl apply -f redis-sts.yaml -f redis-svc.yaml
对于Sts的Pod,有如下特点:
① Pod名固定有序,后缀从0开始;
② “域名”固定,这个“域名”组成: Pod名.Svc名,例如 redis-sts-0.redis-svc;
③ 每个Pod对应的PVC也是固定的;
域名组成
实验: ping 域名
1 $ kubectl exec -it redis-sts-0 -- bash
创建key
1 2 3 4 5 $ kubectl exec -it redis-sts-0 -- redis-cliset k1 'abc' set k2 'bcd'
模拟故障
1 $ kubectl delete pod redis-sts-0
删除后,它会自动重新创建同名Pod,再次进入查看redis key
1 2 3 4 5 $ kubectl exec -it redis-sts-0 -- redis-cli"abc" "bcd"
数据依然存在。
关于Sts里的多个Pod之间的数据同步
7、API资源对象Job 可以理解成一次性运行后就退出的Pod。
1 $ kubectl create job job-demo --image=busybox --dry-run=client -o yaml > job-demo.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 vi job-demo.yaml apiVersion: batch/v1 kind: Job metadata: name: job-demo spec: template: spec: restartPolicy: OnFailure containers: - image: busybox name: job-demo command: ["/bin/echo" ]args: ["hellow" , "world" ]
创建Job
1 $ kubectl apply -f job-demo.yaml
查看Job
可以看到该容器运行完成后状态就变成了Completed。
对于Job,还有几个特殊字段:
activeDeadlineSeconds,设置 Pod 运行的超时时间。
backoffLimit,设置 Pod 的失败重试次数。
completions,Job 完成需要运行多少个 Pod,默认是 1 个。
parallelism,它与 completions 相关,表示允许并发运行的 Pod 数量,避免过多占用资源。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 $ vi myjob.yaml apiVersion: batch/v1 kind: Job metadata: name: sleep-job spec: activeDeadlineSeconds: 15 backoffLimit: 2 completions: 4 parallelism: 2 template: spec: restartPolicy: Never containers: - image: busybox name: echo-job imagePullPolicy: IfNotPresent command: - sh - -c - sleep 10 ; echo done
创建job,并查看job情况
1 $ kubectl apply -f myjob.yaml ; kubectl get pod -w
8、API资源对象CronJob CronJob简称(cj)是一种周期运行的Pod,比如有些任务需要每天执行一次,就可以使用CronJob。
先来生成一个YAML文件:
1 $ kubectl create cj cj-demo --image=busybox --schedule="" --dry-run=client -o yaml > cj-demo.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 $ vi job-demo.yaml apiVersion: batch/v1 kind: CronJob metadata: name: cj-demo spec: schedule: '*/1 * * * *' jobTemplate: spec: template: spec: restartPolicy: OnFailure containers: - image: busybox name: cj-demo imagePullPolicy: IfNotPresent command: ["/bin/echo" ]args: ["hello" , "world" ]
运行并查看
1 2 3 $ kubectl apply -f cj-demo.yaml
9、API资源对象Endpoint Endpoint(简称ep)资源是和Service一一对应的,也就是说每一个Service都会对应一个Endpoint。
1 2 3 4 5 6 7 8 9 10 $ kubectl get ep
Endpoint可以理解成Service后端对应的资源。
有时候K8s里的Pod需要访问外部资源,比如访问外部的MySQL服务,就可以定义一个对外资源的Ednpoint,然后再定义一个Service,就可以让K8s里面的其它Pod访问了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 $ vim testep.yaml apiVersion: v1 kind: Endpoints metadata: name: external-mysql subsets: - addresses: - ip: 192.168 .222 .128 ports: - port: 3306 --- apiVersion: v1 kind: Service metadata: name: external-mysql spec: ports: - port: 3306
应用YAML文件
1 $ kubectl apply -f testep.yaml
测试
1 2 $ kubectl get ep
安装mariadb包(需要mysql命令),然后命令行连接Service external-mysql对应的Cluster IP测试
10、API资源对象ConfigMap 在Kubernetes 1.2中新添加了功能ConfigMap,主要功能是为了解决应用程序会从配置文件、环境变量中获取配置信息。但是默认情况下配置信息需要与docker images解耦,ConfigMap API为我们提供了向容器中注入配置信息的机制,ConfigMap可以被用来保存单个属性,也可以用来保存整个配置文件或者JSON二进制对象
ConfigMap API 资源用来保存key-vlaue pair 配置数据,这个数据可以在pods里使用,或者被用来为contaroller一样的系统组件存储配置数据。ConfigMap 是为了方便的处理不含铭感信息的字符串,你可以将它理解为Linux系统中的/etc目录,专门用来存储配置文件的目录
注意: ConfigMap不是属性配置文件的代替品,ConfigMap只是作为多个properties文件的引用。
ConfigMap(简称cm)用来存储配置信息,比如服务端口、运行参数、文件路径等等。
直接上示例吧:
1 2 3 4 5 6 7 8 9 10 11 12 $ vi mycm.yaml apiVersion: v1 kind: ConfigMap metadata: name: mycm data: DATABASE: 'db' USER: 'wp' PASSWORD: '123456' ROOT_PASSWORD: '123456'
创建cm
1 $ kubectl apply -f mycm.yaml
查看
1 2 $ kubectl get cm
在其它pod里引用ConfigMap
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 $ vi testpod.yaml apiVersion: v1 kind: Pod metadata: name: testpod labels: app: testpod spec: containers: - image: mariadb:10 name: maria imagePullPolicy: IfNotPresent ports: - containerPort: 3306 envFrom: - prefix: 'MARIADB_' configMapRef: name: mycm
验证:
1 $ kubectl exec -it testpod -- bash
11、API资源对象Secret Secret和cm的结构和用法很类似,不过在 K8s里Secret 对象又细分出很多类,比如:
访问私有镜像仓库的认证信息
身份识别的凭证信息
HTTPS 通信的证书和私钥
一般的机密信息(格式由用户自行解释)
前几种我们现在暂时用不到,所以就只使用最后一种。
YAML示例:
1 2 3 4 5 6 7 8 9 10 $ vi mysecret.yaml apiVersion: v1 kind: Secret metadata: name: mysecret data: user: YW1pbmc= passwd: bGludXgxMjM=
查看:
1 2 3 $ kubectl apply -f mysecret.yaml $ kubectl get secret $ kubectl describe secret mysecret
在其它pod里引用Secret
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 $ vi testpod2.yaml apiVersion: v1 kind: Pod metadata: name: testpod2 spec: containers: - image: busybox name: busy imagePullPolicy: IfNotPresent command: ["/bin/sleep" , "300" ]env: - name: USERNAME valueFrom: secretKeyRef: name: mysecret key: user - name: PASSWORD valueFrom: secretKeyRef: name: mysecret key: passwd
查看
1 $ kubectl exec -it testpod2 -- sh