1、前言与架构概述:为什么在 K8s 中选择 Rook-Ceph
在 Kubernetes 环境中,存储一直是架构设计的核心环节。Rook 作为一款云原生的自管理分布式存储编排系统,能够为 K8s 提供极为便利的存储解决方案。
Rook 的核心定位在于它本身不提供存储,而是充当 Kubernetes 与存储系统(如 Ceph)之间的适配层。它将存储软件转变为可管理的 Kubernetes 服务,从而极大地简化了存储系统的部署与维护工作。目前,Rook 已支持 Ceph、CockroachDB、Cassandra、EdgeFS、Minio、NFS 等多种存储系统,其中对 Ceph 和 NFS 的支持最为成熟。
为什么选择 Rook 部署 Ceph?
- 官方推荐:Ceph 官方社区推荐使用 Rook 作为在 Kubernetes 中部署和管理 Ceph 的主要方式。
- 原生集成:完全通过 Kubernetes 原生机制与存储数据交互,运维人员无需手动编写复杂的 Ceph 命令行配置,降低了运维门槛。。
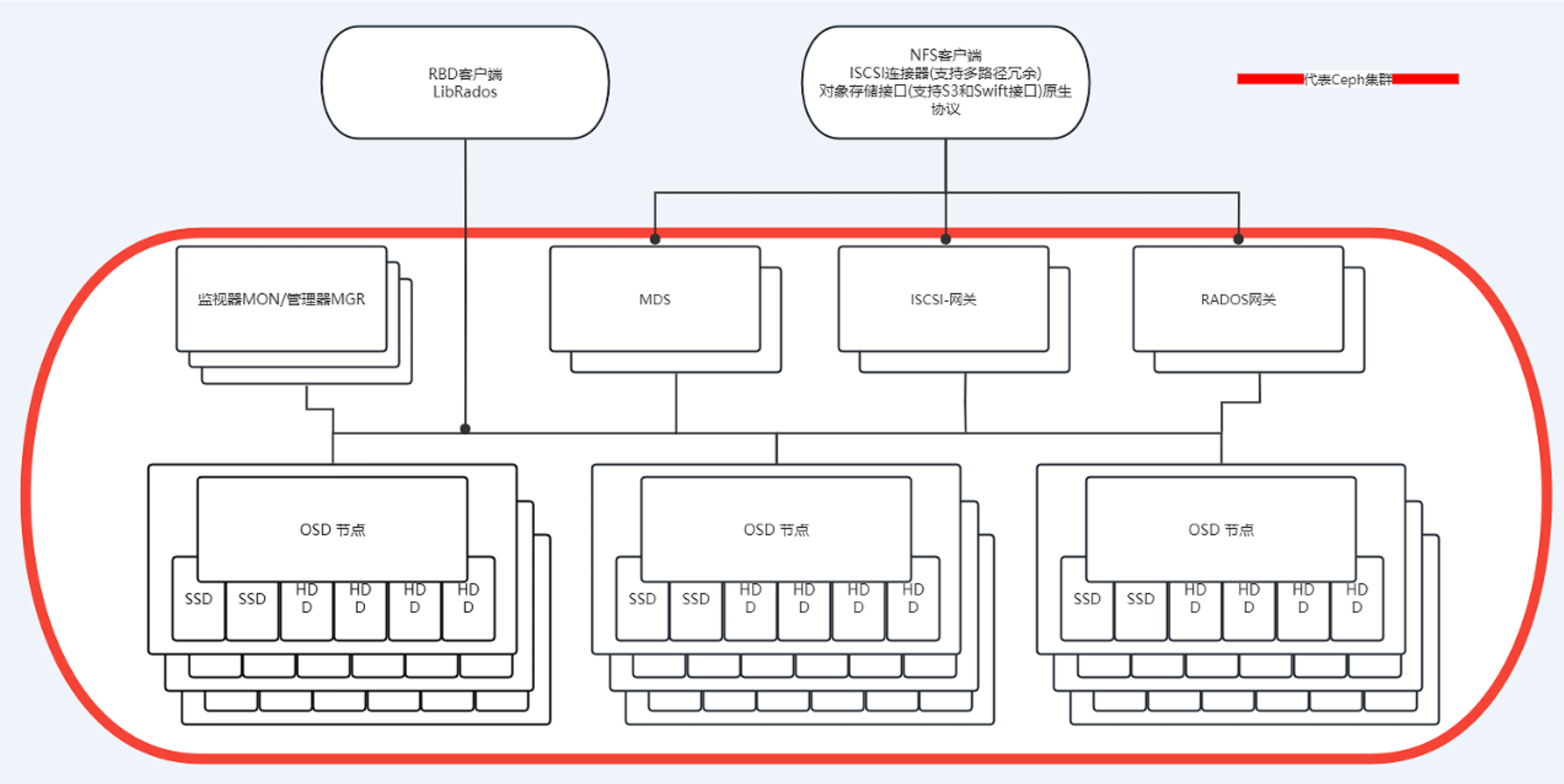
2、Ceph介绍
Ceph 是一种为高性能、可靠性和可扩展性设计的统一分布式文件系统。
- 统一性:同时提供块存储(RBD)、文件系统(CephFS)和对象存储(RADOSGW)。
- 分布式:支持动态扩展,能够应对 PB 级别的数据增长。
核心组件详解 Ceph 集群的高效运行依赖于以下三个核心组件的协作:
- OSD (Object Storage Daemon):负责存储集群中的所有数据与对象,处理数据复制、恢复、再均衡,并通过心跳机制向 Monitor 汇报状态。
- Monitor (MON):监控整个集群的拓扑结构和健康状态,维护集群地图,并处理客户端的认证与授权,确保数据一致性。
- MDS (Metadata Server):专门负责保存文件系统的元数据(如目录结构)。注意,对象存储和块设备存储不需要 MDS 服务。

3、从 Operator 到 Ceph 集群的搭建
3.1 环境要求
在生产环境中部署 Rook-Ceph 需要严格的环境预检,以避免后期因硬件或系统配置问题导致集群不稳定。
硬件与节点要求
- Kubernetes 版本:Rook 支持 K8s v1.19 及以上版本,本文基于 v1.34.3 演示,使用 Rook v1.18.9(兼容 K8s v1.29~v1.34)。
- 节点数量:至少 3 个节点,且均可调度 Pod,以满足 Ceph 副本的高可用要求。
- CPU 架构:支持 x86_64 或 arm64。
存储设备准备
Ceph 对存储设备有特定要求,必须使用以下类型的存储选项之一:
- 原始磁盘设备(无分区、无文件系统)
- 原始分区(无文件系统)
- LVM 逻辑卷(无文件系统)
- 持久卷(PV,来自 StorageClass 的块模式)
3.2 准备工作
本文k8s集群部署在vmware虚拟化中,需要先给节点添加一块硬盘。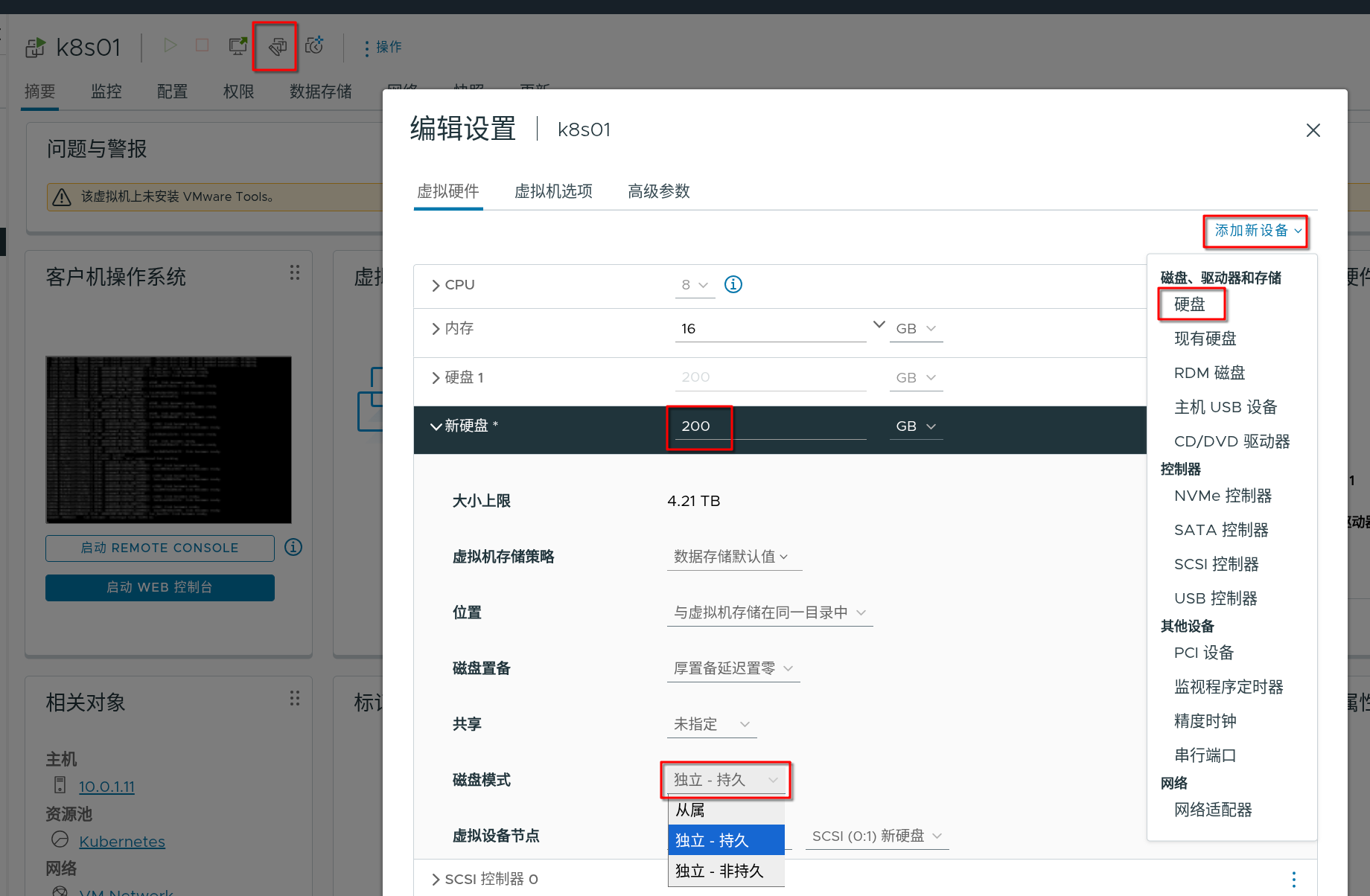
将新增的磁盘设置成独立模式(模拟公有云厂商提供的独立磁盘),在工作节点上使用以下命令检查一下磁盘条件是否符合Ceph部署要求:
[root@k8s01 ~]# lsblk -f
NAME FSTYPE FSVER LABEL UUID FSAVAIL FSUSE% MOUNTPOINTS
sda
├─sda1 vfat FAT32 4B54-D29C 592.6M 1% /boot/efi
├─sda2 ext4 1.0 1e8a5651-2e89-45e0-93de-df0fb8e3bfa3 704.7M 21% /boot
└─sda3 LVM2_member LVM2 001 Ngewk7-z9UP-3ydQ-2khE-U6KI-4dWB-AuBXNk
├─openeuler-root ext4 1.0 97424f44-54d9-4cbb-9c5d-56cd55616740 157.2G 5% /
└─openeuler-home ext4 1.0 6c68b988-8956-4cc3-be4b-2f476d03fc4a 18.5G 0% /home
sdb 上述命令输出中 sdb 磁盘就是我们为工作节点新添加的裸设备(它的FSTYPE为空),我们可以把它分配给Ceph使用。
下载rook示例清单
$ git clone --single-branch --branch v1.18.9 https://github.com/rook/rook.git(可选)修改Rook CSI驱动注册路径
注意:rook csi驱动挂载的路径是挂载到kubelet所配置的参数指定的目录下的;所以需要根据自己实际的-root-dir参数修改下图中rook csi的kubelet路径地址;如果与实际kubelet的-root-dir路径不一致,则会导致后面进行挂载存储时提示driver name rook-ceph.cephfs.csi.ceph.com not found in the list of registered CSI driver。
默认的安装都是在/var/lib/kubelet/基本上不用修改,如果非默认需要更改;
$ grep "ROOK_CSI_KUBELET_DIR_PATH" rook/deploy/examples/operator.yaml
# ROOK_CSI_KUBELET_DIR_PATH: "/var/lib/kubelet"对所有需要安装ceph的work节点安装LVM2
$ yum install lvm2 -y
#检查是否安装成功
$ yum list installed | grep lvm2
lvm2.x86_64 8:2.03.14-9.el8 @anaconda
lvm2-libs.x86_64 8:2.03.14-9.el8 @anaconda在K8S集群中运行Ceph OSD的所有存储节点上都需要有这个包。虽然没有这个包Rook也能够成功创建Ceph OSD,但是当相应的节点(node)重启之后,其上运行的OSD pod将会启动失败。所以需要确保作为存储节点的操作系统上安装了LVM(从上面磁盘条件查验的结果中看到我们是有LVM卷的)。
Ceph需要一个带有RBD模块的Linux内核
大多数Linux发行版都有这个模块,但不是所有,你可以在K8S集群的存储节点上运行lsmod|grep rbd命令检测一下,如果该命令返回空,那说明当前系统内核没有加载RBD模块,可以使用以下命令尝试加载RBD模块:
# 将RBD模块加载命令放入开机加载项里
$ cat > /etc/sysconfig/modules/rbd.modules << EOF
#! /bin/bash
modprobe rbd
EOF
# 为上述为脚本添加执行权限
$ chmod +x /etc/sysconfig/modules/rbd.modules
# 执行上述脚本(如果返回'not found',你可能需要安装一个新的内核、或重新编译一个带有RBD模块的内核、或换一个带有RBD的Linux 发行版)
$ /bin/bash /etc/sysconfig/modules/rbd.modules
# 查看RBD模块是否加载成功
$ lsmod|grep rbd3.3 部署Ceph集群
使用Rook官方提供的示例部署组件清单(manifests)部署一个Ceph集群:
$ cd rook/deploy/examples
kubectl create -f crds.yaml -f common.yaml -f csi-operator.yaml接下来部署Rook Operator组件,该组件为Rook与Kubernetes交互的组件,整个集群只需要一个副本,特别注意 Rook Operator 的配置在Ceph集群安装后不能修改,否则Rook会删除Ceph集群并重建,所以部署之前一定要做好规划,修改好operator.yaml 的相关配置:
修改rook/deploy/examples/operator.yaml文件中的以下内容:
# 打开CephCSI 提供者的节点(node)亲和性(去掉前面的注释即可,会同时作用于CephFS和 RBD提供者,如果要分开这两者的调度,可以继续打开后面专用的节点亲和性)
CSI_PROVISIONER_NODE_AFFINITY: "role=storage-node; storage=rook-ceph"
# 如果CephFS和RBD提供者的调度亲各性要分开,则在上面的基础上继打开它们专用的开关(去 除下面两行前端的#即可)
# CSI_RBD_PROVISIONER_NODE_AFFINITY: "role=rbd-node"
# CSI_CEPHFS_PROVISIONER_NODE_AFFINITY: "role=cephfs-node"
# 打开CephCSI 插件的节点(node)亲和性(去掉前面的注释即可,会同时作用于CephFS和RBD 插件,如果要分开这两者的调度,可以继续打开后面专用的节点亲和性)
CSI_PLUGIN_NODE_AFFINITY: "role=storage-node; storage=rook-ceph"
# 如果CephFS和RBD提供者的调度亲各性要分开,则在上面的基础上继打开它们专用的开关(去除下面两行前端的#即可)
# CSI_RBD_PLUGIN_NODE_AFFINITY: "role=rbd-node"
# CSI_CEPHFS_PLUGIN_NODE_AFFINITY: "role=cephfs-node"
# 生产环境一般还会打开裸设备自动发现守护进程(方便后期增加设备)
ROOK_ENABLE_DISCOVERY_DAEMON: "true"
# 同时打开发现代理的节点亲和性环境变量,在551行
551 DISCOVER_AGENT_NODE_AFFINITY: |
552 requiredDuringSchedulingIgnoredDuringExecution:
553 nodeSelectorTerms:
554 - matchExpressions:
555 - key: role
556 operator: In
557 values:
558 - storage-node
559 - key: storage
560 operator: In
561 values:
562 - rook-ceph确认修改完成后,在master节点上执行以下命令进行Rook Ceph Operator的部署:
# 执行以下命令在K8S集群中部署Rook Ceph Operator(镜像拉取可能需要一定时间,耐心等待,可用后一条命令监控相关Pod部署情况)
$ kubectl create -f operator.yaml
# 使用以下命令监控Rook Ceph Operator相关Pod的部署情况(rook-ceph为默认Rook Ceph Operator部署命名空间)
$ watch kubectl get pods -n rook-ceph确保rook-ceph-operator相关Pod都运行正常的情况下,修改rook/deploy/examples/cluster.yaml文件中的以下内容:
# enable prometheus alerting for cluster
monitoring:
# requires Prometheus to be pre-installed
enabled: false #如果集群中没有安装prometheus的小伙伴不要开启!!
# To control where various services will be scheduled by kubernetes, use the placement configuration sections below.
# The example under 'all' would have all services scheduled on kubernetes nodes labeled with 'role=storage-node' and
# tolerate taints with a key of 'storage-node'.
placement:
all:
nodeAffinity: #打开节点亲和性调度和污点容忍
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: role
operator: In
values:
- storage-node
# podAffinity:
# podAntiAffinity:
# topologySpreadConstraints:
# tolerations:
# - key: storage-node
# operator: Exists
storage: # cluster level storage configuration and selection
useAllNodes: false
useAllDevices: false
#deviceFilter:
config:
# crushRoot: "custom-root" # specify a non-default root label for the CRUSH map
# metadataDevice: "md0" # specify a non-rotational storage so ceph-volume will use it as block db device of bluestore.
# databaseSizeMB: "1024" # uncomment if the disks are smaller than 100 GB
# journalSizeMB: "1024" # uncomment if the disks are 20 GB or smaller
# osdsPerDevice: "1" # this value can be overridden at the node or device level
# encryptedDevice: "true" # the default value for this option is "false"
# Individual nodes and their config can be specified as well, but 'useAllNodes' above must be set to false. Then, only the named
# nodes below will be used as storage resources. Each node's 'name' field should match their 'kubernetes.io/hostname' label.
nodes:
- name: "k8s01" # 注意,name 不能够配置为IP,而应该是标签 kubernetes.io/hostname 的内容
devices: # specific devices to use for storage can be specified for each node
- name: "sdb" # 将存储设置为我们三个工作节点新加的sdb裸盘,可以通过 lsblk查看磁盘信息
- name: "k8s02"
devices: # specific devices to use for storage can be specified for each node
- name: "sdb"
- name: "k8s03"
devices: # specific devices to use for storage can be specified for each node
- name: "sdb"
# - name: "nvme01" # multiple osds can be created on high performance devices
# config:
# osdsPerDevice: "5"
# - name: "/dev/disk/by-id/ata-ST4000DM004-XXXX" # devices can be specified using full udev paths
# config: # configuration can be specified at the node level which overrides the cluster level config
# - name: "172.17.4.301"
# deviceFilter: "^sd."
# when onlyApplyOSDPlacement is false, will merge both placement.All() and placement.osd
onlyApplyOSDPlacement: false
当 onlyApplyOSDPlacement: false 时(默认行为)
OSD 会同时继承: placement.all + placement.osd
也就是说:
placement.all 里的 nodeAffinity / tolerations / resources
placement.osd 里的 nodeAffinity / tolerations / resources
都会应用到 OSD Pod 上
当 onlyApplyOSDPlacement: true 时OSD 只使用:placement.osd
这个参数的使用场景
场景 1:你想统一控制所有组件
用 placement.all
onlyApplyOSDPlacement: false(默认)
场景 2:你想给 OSD 完全单独调度规则
比如:OSD 跑在裸盘节点
MON/MGR 跑在 control-plane
用:onlyApplyOSDPlacement: true先修改一下集群osd的资源限制,否则osd的内存使用率会无限增长(经验教训)
# 在244行处加入资源限制,建议内存设置4G以上,同时需要注意yaml文件的格式。
resources:
osd:
limits:
cpu: "2"
memory: "8000Mi"
requests:
cpu: "2"
memory: "8000Mi"部署等待(部署需要一定的时间,可用后一条命令监控)
# 确保工作节点打上对应标签,并且cluster文件修改好后,就可以使用cluster.yaml部署 Ceph存储集群了
$ kubectl create -f cluster.yaml
# 使用以下命令监控Ceph Cluster相关Pod的部署情况(rook-ceph为默认部署命名空间)
$ watch kubectl get pods -n rook-ceph查看最终Pod的状态
$ kubectl get pods -n rook-ceph
NAME READY STATUS RESTARTS AGE
ceph-csi-controller-manager-6fdd9498b7-nhvtg 1/1 Running 0 30m
rook-ceph-crashcollector-k8s01-64ddb84f64-t2tkl 1/1 Running 0 6m10s
rook-ceph-crashcollector-k8s02-9b5b84df9-rvz8p 1/1 Running 0 6m7s
rook-ceph-crashcollector-k8s03-6ddf498b78-h5qh8 1/1 Running 0 6m32s
rook-ceph-exporter-k8s01-7fdbb4b74f-22xgq 1/1 Running 0 6m7s
rook-ceph-exporter-k8s02-658b455798-2zr4n 1/1 Running 0 6m4s
rook-ceph-exporter-k8s03-54884bd4cf-p9rqv 1/1 Running 0 6m32s
rook-ceph-mgr-a-6d9b4cbd4f-55j94 3/3 Running 0 6m45s
rook-ceph-mgr-b-bcbc75d6f-hxn4l 3/3 Running 0 6m43s
rook-ceph-mon-a-55cb7d475c-qdcv7 2/2 Running 0 7m32s
rook-ceph-mon-b-68976d7c74-4dd65 2/2 Running 0 7m9s
rook-ceph-mon-c-85dddfdd54-ltxwn 2/2 Running 0 7m
rook-ceph-operator-845844977b-v2tp6 1/1 Running 0 14m
rook-ceph-osd-0-55d98df84-h79w5 2/2 Running 0 6m10s
rook-ceph-osd-1-58c5b48cf9-shb5r 2/2 Running 0 6m8s
rook-ceph-osd-2-796858cbbd-67gc8 2/2 Running 0 6m6s
rook-ceph-osd-prepare-k8s01-qqcmb 0/1 Completed 0 6m21s
rook-ceph-osd-prepare-k8s02-xdllc 0/1 Completed 0 6m20s
rook-ceph-osd-prepare-k8s03-mc5t4 0/1 Completed 0 6m20s
rook-ceph.cephfs.csi.ceph.com-ctrlplugin-9f764cd5c-6d2q5 5/5 Running 0 7m39s
rook-ceph.cephfs.csi.ceph.com-ctrlplugin-9f764cd5c-r9ksb 5/5 Running 0 7m39s
rook-ceph.cephfs.csi.ceph.com-nodeplugin-f25pc 2/2 Running 0 7m39s
rook-ceph.cephfs.csi.ceph.com-nodeplugin-wfqlc 2/2 Running 0 7m39s
rook-ceph.cephfs.csi.ceph.com-nodeplugin-z444c 2/2 Running 0 7m39s
rook-ceph.rbd.csi.ceph.com-ctrlplugin-688d48cbc7-v8t98 5/5 Running 0 7m39s
rook-ceph.rbd.csi.ceph.com-ctrlplugin-688d48cbc7-vc9bz 5/5 Running 0 7m39s
rook-ceph.rbd.csi.ceph.com-nodeplugin-njhzd 2/2 Running 0 7m39s
rook-ceph.rbd.csi.ceph.com-nodeplugin-wrxpl 2/2 Running 0 7m39s
rook-ceph.rbd.csi.ceph.com-nodeplugin-x56vb 2/2 Running 0 7m39s
rook-discover-689hk 1/1 Running 0 14m
rook-discover-f5ldc 1/1 Running 0 14m
rook-discover-gnvsg 1/1 Running 0 14m以上是所有组件 pod 完成后的状态,以 rook-ceph-osd-prepare 开头的 pod 用于自动感知集群新挂载硬盘,只不过我们前面手动指定了节点,所以这个不起作用。osd-0、osd-1、osd-2容器必须是存在且正常的,如果上述pod均正常运行成功,则视为集群安装成功。
如果部署成功一次后重新部署需要对磁盘重写,因为磁盘已经具有一个特定的 UUID,表示该磁盘已被使用,可以查看rook-ceph-osd-prepare的logs判断是否属于这种情况,使用如下命令解决
$ dd if=/dev/zero of="/dev/sdb" bs=1M count=100 oflag=direct,dsync # 每一台ceph节点都要执行
$ kubectl delete pod rook-ceph-operator-578869b6b5-dnzhz -n rook-ceph # 删除operator,使其重新检测
# 重新部署时需要删除/var/lib/rook
$ rm -rf /var/lib/rook3.4 开启prometheus
如果是使用自建prometheus,需要在config添加如下内容
- job_name: rook-ceph/rook-ceph-mgr/0
honor_labels: false
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- rook-ceph
scrape_interval: 5s
metrics_path: /metrics
relabel_configs:
- action: keep
source_labels:
- __meta_kubernetes_service_label_app
regex: rook-ceph-mgr
- action: keep
source_labels:
- __meta_kubernetes_service_label_rook_cluster
regex: rook-ceph
- action: keep
source_labels:
- __meta_kubernetes_endpoint_port_name
regex: http-metrics
- source_labels:
- __meta_kubernetes_endpoint_address_target_kind
- __meta_kubernetes_endpoint_address_target_name
separator: ;
regex: Node;(.*)
replacement: ${1}
target_label: node
- source_labels:
- __meta_kubernetes_endpoint_address_target_kind
- __meta_kubernetes_endpoint_address_target_name
separator: ;
regex: Pod;(.*)
replacement: ${1}
target_label: pod
- source_labels:
- __meta_kubernetes_namespace
target_label: namespace
- source_labels:
- __meta_kubernetes_service_name
target_label: service
- source_labels:
- __meta_kubernetes_pod_name
target_label: pod
- source_labels:
- __meta_kubernetes_service_name
target_label: job
replacement: ${1}
- target_label: endpoint
replacement: http-metrics4、安装 ceph 扩展
4.1 部署ceph dashboard
Ceph Dashboard 是一个内置的基于 Web 的管理和监视应用程序,它是开源 Ceph 发行版的一部分。通过 Dashboard 可以获取 Ceph 集群的各种基本状态信息。
$ cd rook/deploy/examples
$ kubectl apply -f dashboard-external-https.yaml创建NodePort类型就可以被外部访问了
$ kubectl get svc -n rook-ceph|grep dashboard
rook-ceph-mgr-dashboard ClusterIP 109.233.40.229 <none> 8443/TCP 8m28s
rook-ceph-mgr-dashboard-external-https NodePort 109.233.34.181 <none> 8443:32234/TCP 29s浏览器访问(master1-ip换成自己的集群ip):https://master-ip:32234/ (访问地址,注意是https,http会访问不成功)
Rook 创建了一个默认的用户 admin,并在运行 Rook 的命名空间中生成了一个名为rook-ceph-dashboard-admin-password的 Secret,要获取密码,可以运行以下命令:
$ kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}"|base64 --decode && echo
4.2 部署Ceph工具
Rook 工具箱是一个包含用于 Rook 调试和测试的常用工具的容器
$ cd rook/deploy/examples
$ kubectl apply -f toolbox.yaml -n rook-ceph待容器Running后,即可执行相关命令:
$ kubectl exec -it `kubectl get pods -n rook-ceph|grep rook-ceph-tools|awk '{print $1}'` -n rook-ceph -- bash
[rook@rook-ceph-tools-775f4f4468-dcg4x /]$ ceph -s
cluster:
id: b79e201e-5843-4dd1-83bc-86c54c16dfbc
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 67m)
mgr: a(active, since 7m), standbys: b
osd: 3 osds: 3 up (since 7m), 3 in (since 33m)
data:
pools: 1 pools, 1 pgs
objects: 2 objects, 449 KiB
usage: 63 MiB used, 600 GiB / 600 GiB avail
pgs: 1 active+clean
[rook@rook-ceph-tools-775f4f4468-dcg4x /]$ ceph osd status
ID HOST USED AVAIL WR OPS WR DATA RD OPS RD DATA STATE
0 k8s01 26.9M 199G 0 0 0 0 exists,up
1 k8s02 26.9M 199G 0 0 0 0 exists,up
2 k8s03 26.9M 199G 0 0 0 0 exists,up总结
至此通过Rook的这种方式成功的在K8S集群中部署了ceph服务,这种方式可以直接在生产环境使用。同时也可以看到使用Rook安装Ceph还是很简单的,只需要执行对应的yaml文件即可。
- 线上环境如有公有云不建议自己搭建CEPH集群;
- 部署搭建只是第一步,后续的优化及维护是重点,如没有相关经验不推荐直接线上使用;
- 数据永远是公司最宝贵的资源之一,一定要能扛起敬畏数据的责任;
5、存储类配置:RBD 与 CephFS 的 K8s 持久化集成
5.1 部署 RBD StorageClass
Ceph 可以同时提供对象存储 RADOSGW、块存储 RBD、文件系统存储 Ceph FS。
RBD 即 RADOS Block Device 的简称,RBD 块存储是最稳定且最常用的存储类型。
RBD 块设备类似磁盘可以被挂载。
RBD 块设备具有快照、多副本、克隆和一致性等特性,数据以条带化的方式存储在 Ceph 集群的多个 OSD 中。注意: RBD只支持ReadWriteOnce存储类型!
1、创建 StorageClass
$ cd rook/deploy/examples/csi/rbd
$ kubectl apply -f storageclass.yaml2、校验pool安装情况
$ kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') -- bash
[root@rook-ceph-tools-775f4f4468-dcg4x /]# ceph osd lspools
1 .mgr
2 replicapool3、查看StorageClass
$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate true 38s4、将Ceph设置为默认存储卷
$ kubectl patch storageclass rook-ceph-block -p '{"metadata":{"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'修改完成后再查看StorageClass状态(有个default标识)
$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
rook-ceph-block(default) rook-ceph.rbd.csi.ceph.com Delete Immediate true 43s5、测试验证
创建pvc指定 storageClassName 为 rook-ceph-block
[root@master code]# cat rbd-pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-mysql-data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
storageClassName: rook-ceph-block5.2 部署 CephFS StorageClass
CephFS 允许用户挂载一个兼容posix的共享目录到多个主机,该存储和NFS共享存储以及CIFS共享目录相似;
1、创建 StorageClass
$ cd rook/deploy/examples/csi/cephfs
$ kubectl apply -f storageclass.yaml2、查看StorageClass
$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate true 12m
rook-cephfs rook-ceph.rbd.csi.ceph.com Delete Immediate true 57scephfs使用和rbd同样指定storageClassName的值便可,须要注意的是rbd只支持 ReadWriteOnce,cephfs能够支持ReadWriteMany 。
3、测试验证
$ cat cephfs-pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: redis-data-pvc
spec:
accessModes:
#- ReadWriteOnce
- ReadWriteMany
resources:
requests:
storage: 2Gi
storageClassName: rook-cephfs建立一个pod来使用pvc做存储并验证持久化效果(如果不是所有节点加入了ceph集群,需要添加节点选择器,在运行csi的节点上才可以正常挂载)
$ cat test-cephfs-pod.yml
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis:4-alpine
ports:
- containerPort: 6379
name: redisport
volumeMounts:
- mountPath: /data
name: redis-pvc
nodeSelector:
role: storage-node
volumes:
- name: redis-pvc
persistentVolumeClaim:
claimName: redis-data-pvc$ kubectl exec -it redis -- sh
/data #
/data # ls
/data # redis-cli
127.0.0.1:6379> set mykey "hello world"
OK
127.0.0.1:6379> get mykey
"hello world"
127.0.0.1:6379> BGSAVE
Background saving started
127.0.0.1:6379> exit
/data # ls
dump.rdb
# 删除pod
$ kubectl delete -f test-cephfs-pod.yml pod "redis" deleted
# 再次创建pod
$ kubectl apply -f test-cephfs-pod.yml pod/redis created
# 验证数据持久化
$ kubectl exec -it redis -- sh
/data #
/data # redis-cli 127.0.0.1:6379> get mykey
"hello world"6、场景选型与最佳实践:RBD vs CephFS 及避坑指南
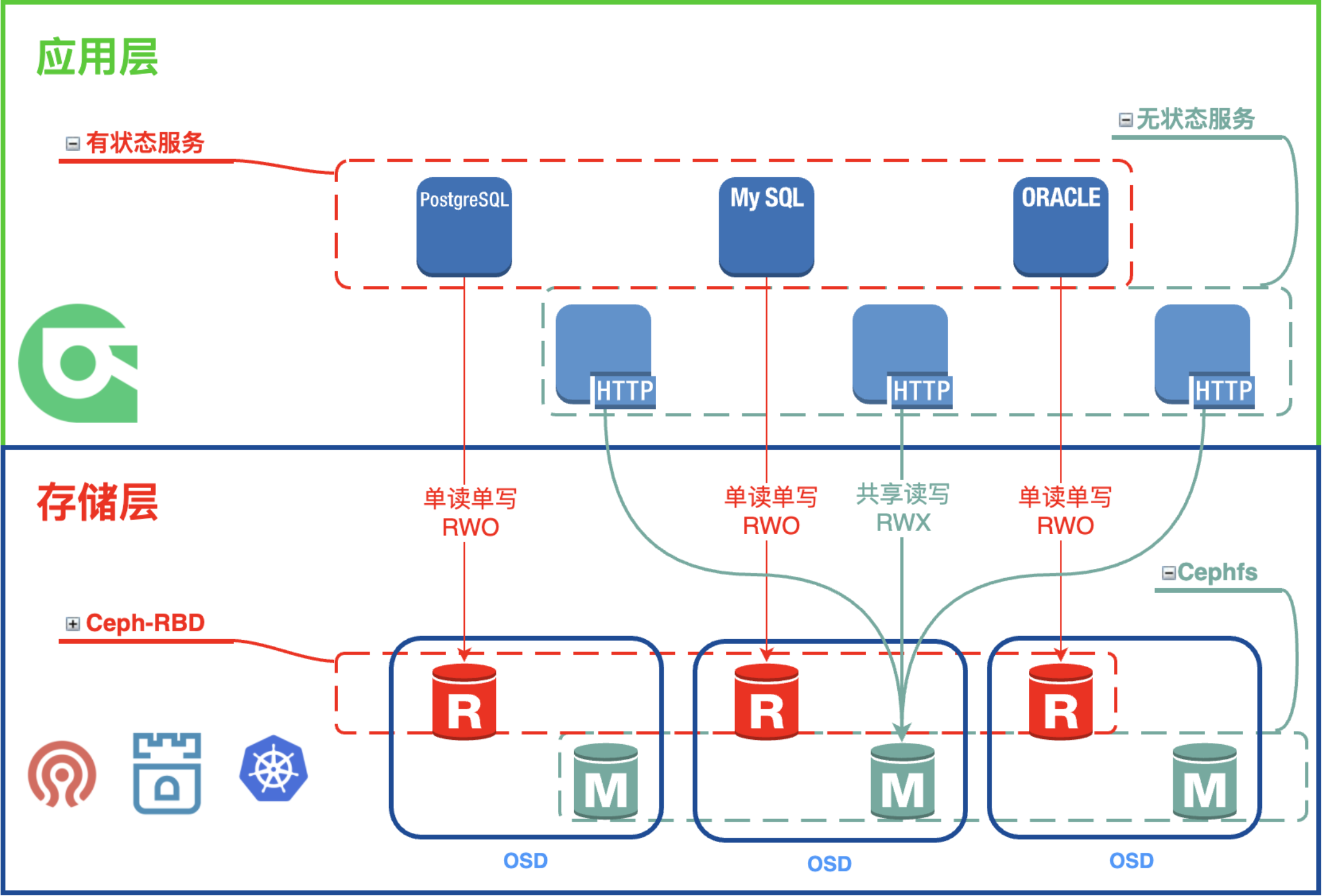
| 特性 | Ceph RBD (块存储) | CephFS (文件系统) |
|---|---|---|
| 读写模式 | ReadWriteOnce (RWO) | ReadWriteMany (RWX) |
| 性能 | 低延迟,高带宽 | 大文件性能好,小文件读写延迟偏高 |
| 特性 | 支持快照、克隆 | 支持共享目录、POSIX 兼容 |
| 适用场景 | 数据库(MySQL, PostgreSQL等)对 I/O 延迟敏感的场景 | 中间件、应用共享存储(如日志共享、多节点并发读写) |
生产环境最佳实践与避坑指南
- 资源限制是底线:务必在
cluster.yaml中为 OSD Pod 设置 Memory Limits,防止 Ceph 耗尽节点内存导致系统崩溃。 - 磁盘规划:生产环境建议使用独立磁盘而非根分区,并确保磁盘类型一致(如全部 SSD 或全部 HDD),避免混合存储带来的性能抖动。
- 数据敬畏:Ceph 集群的维护专业性较强。如果是公有云环境,建议直接使用云厂商提供的块存储;自建 Ceph 需要团队具备相应的运维能力。
- 故障处理:遇到 OSD 无法启动时,首先检查磁盘是否被旧数据占用,必要时使用
dd命令清空磁盘元数据。 - 监控告警:务必集成 Prometheus 监控,关注
OSD Down、PG State等关键指标,防患于未然。
通过以上步骤,您已成功在 Kubernetes 集群中构建了一套生产可用的 Rook-Ceph 存储系统。合理利用 RBD 和 CephFS 的特性,能够完美解决容器化应用对持久化存储的多样化需求。

hello world
hello world