
1、前言
Rook https://rook.io 是一个自管理的 分布式存储 编排系统,可以为Kubernetes提供便利的存储解决方案。
Rook本身并不提供存储,而是在kubernetes和存储系统之间提供适配层,简化存储系统的部署与维护工作。
目前,Rook支持的存储系统包括:Ceph、CockroachDB、Cassandra、EdgeFS、 Minio、NFS。当然,Rook支持的最好的还是Ceph 和 NFS。
为什么要使用Rook?
- Ceph 官方推荐 使用Rook进行部署管理;
- 它是通过原生的Kubernetes机制和数据存储交互。意味着你不再需要通过命令行手 动配置Ceph。
2、Ceph介绍
Ceph 是一种为优秀的性能、可靠性和可扩展性而设计的统一的、分布式文件系统。
Ceph 的统一体现在可以提供文件系统、块存储和对象存储,分布式体现在可以动态扩展。
Ceph支持三种存储:
- 块存储(RDB): 可以直接作为磁盘挂载;
- 文件系统(CephFS): 兼容的网络文件系统CephFS,专注于高性能、大容量存储;
- 对象存储(RADOSGW): 提供RESTful接口,也提供多种编程语言绑定。兼容S3 (是AWS里的对象存储)、Swift(是openstack里的对象存储)
2.1 核心组件
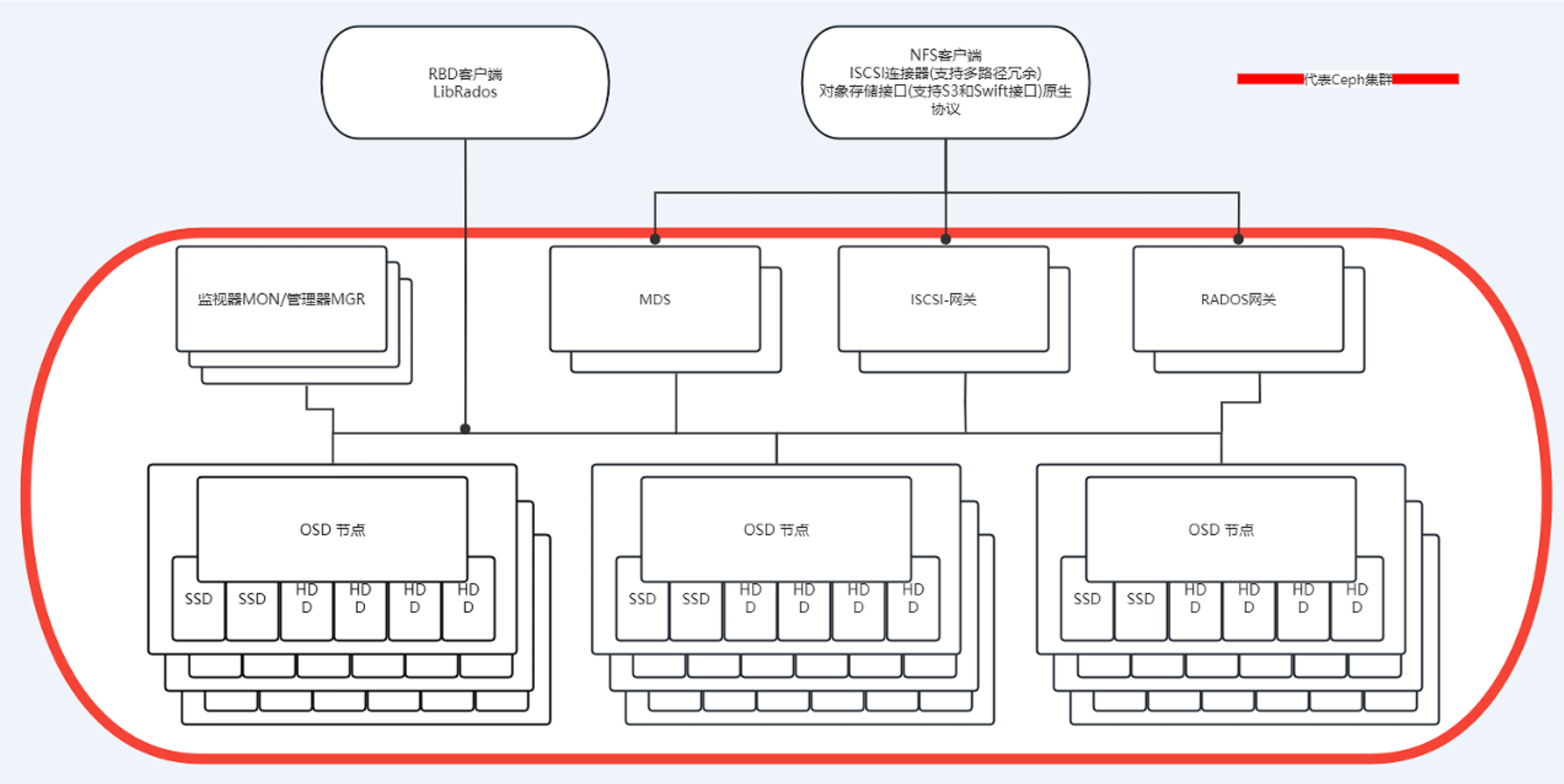
Ceph 主要有三个核心组件:
- OSD 用于集群中所有数据与对象的存储,处理集群数据的复制、恢复、回填、再均衡,并向其他osd守护进程发送心跳,然后向 Monitor 提供一些监控信息。
- Monitor 监控整个集群的状态,管理集群客户端认证与授权,保证集群数据的一致性;
- MDS 负责保存文件系统的元数据,管理目录结构。对象存储和块设备存储不需要元数据服务;
3、安装Ceph集群
Rook支持K8S v1.19+的版本,CPU架构为x86_64或arm64均可。
通过rook安装ceph集群 必须满足以下先决条件:
- 至少准备3个节点、并且全部可以调度pod,满足ceph副本高可用要求
- 已部署好的Kubernetes集群
- OSD节点每个节点至少有一块裸设备(Raw devices,未分区未进行文件系统格式化)
3.1 ceph在K8S的部署
这里我们选择为K8S集群的 每个工作节点 添加一块额外的未格式化磁盘(裸设备)
以vMware workstation为例
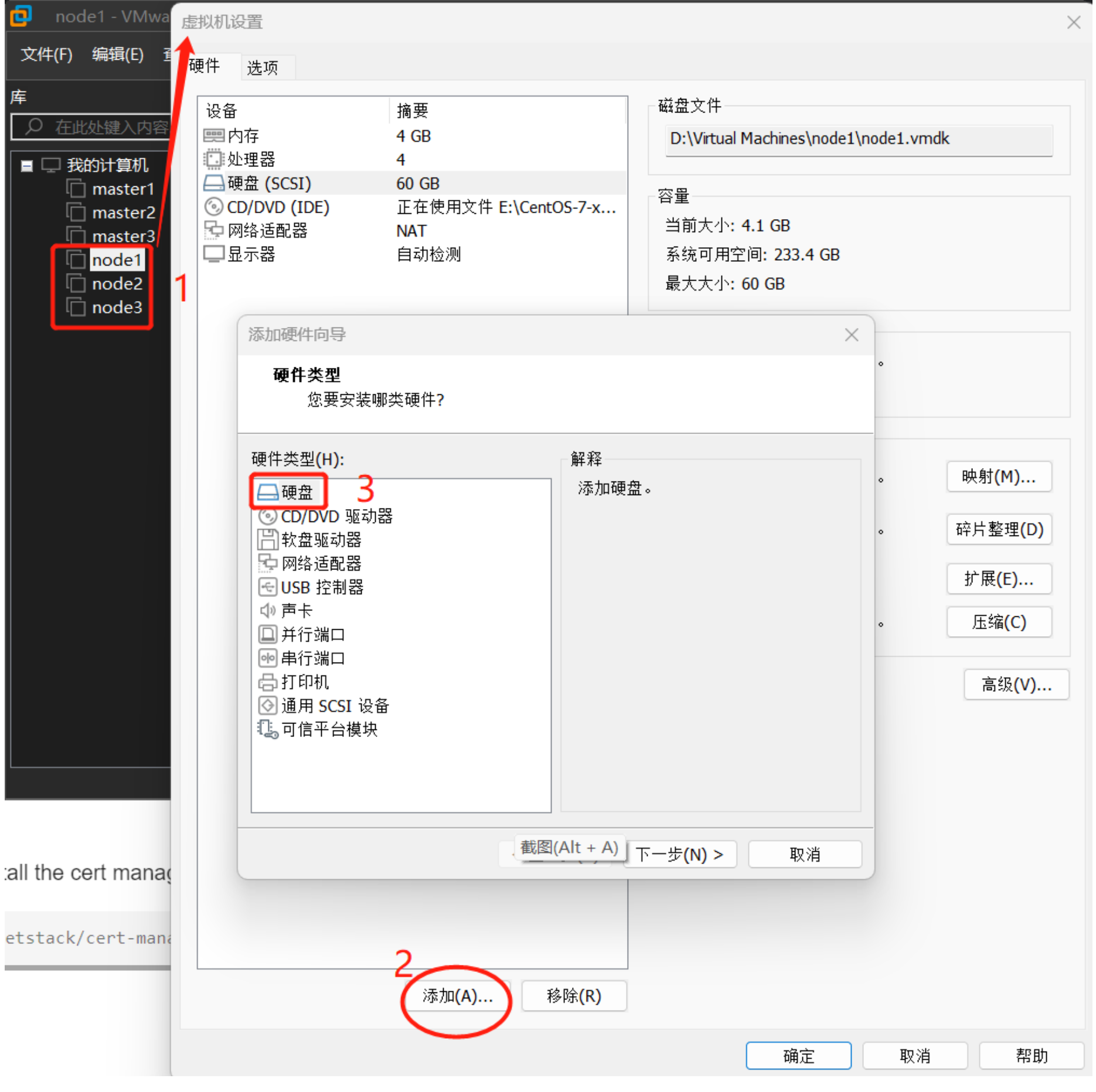
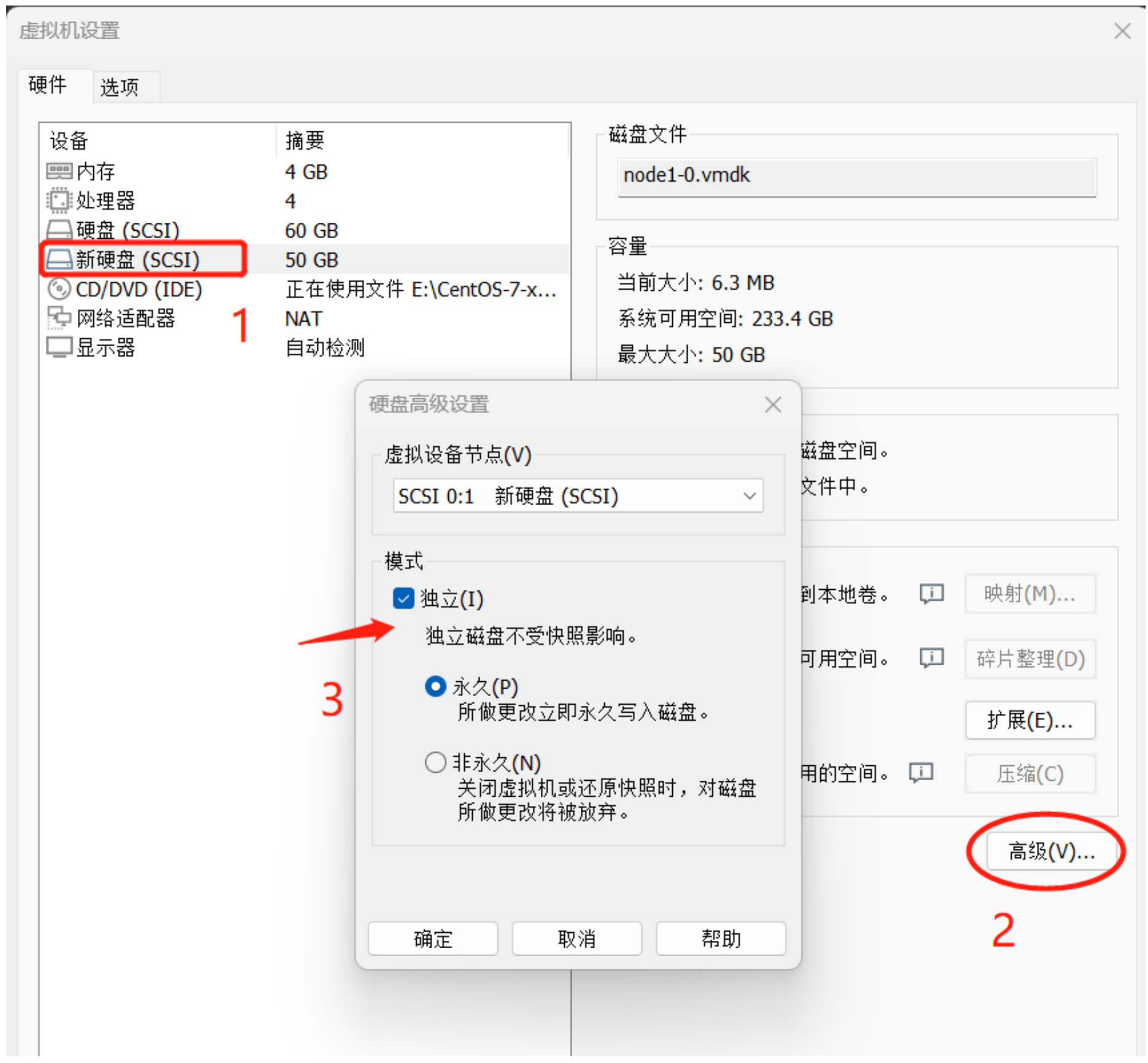
将新增的磁盘设置成独立模式(模拟公有云厂商提供的独立磁盘),然后启动K8S集群虚拟机,在工作节点上使用以下命令检查一下磁盘条件是否符合Ceph部署要求:
$ lsblk -f
NAME FSTYPE LABEL UUID MOUNTPOINT
sda
├─sda1 xfs 8e4061b2-6641-4454-8cfa-9e3d790ef7d0 /boot
└─sda2 LVM2_member lwt3tx-c7E6-soF9-JbZw-gDUe-HnhG-WVXiWP
├─rl-root xfs 676e3e2e-3deb-4f14-9ef9-e6bdcefb9bf5 /
├─rl-swap swap a512e95f-98b6-434d-9731-14d98e274b03
└─rl-home xfs 7e2dd21c-d028-45f7-8b41-79afb01da07f /home
sdb
sr0 iso9660 Rocky-8-8-x86_64-dvd 2023-05-17-23-36-02-00上述命令输出中 sdb 磁盘就是我们为工作节点新添加的裸设备(它的FSTYPE为空),我们可以把它分配给Ceph使用。
下载rook示例清单
$ git clone --single-branch --branch v1.12.8 https://github.com/rook/rook.git修改Rook CSI驱动注册路径
注意:rook csi驱动挂载的路径是挂载到kubelet所配置的 参数指定的目录下的;所以需要根据自己实际的-root-dir参数修改下图中rook csi的kubelet路径地址;如果与实际kubelet的-root-dir路径不一致,则会导致后面进行挂载存储时提示driver name rook-ceph.cephfs.csi.ceph.com not found in the list of registered CSI driver
默认的安装都是在/var/lib/kubelet/基本上不用修改,如果非默认需要更改;
# vim rook/deploy/examples/operator.yaml
144 ROOK_CSI_KUBELET_DIR_PATH
需要在K8S集群中启用Rook准入控制器。该准入控制器在身份认证和授权之后并在持久化对象之前,拦截发往K8S API Server的请求以进行验证。我们在安装Rook之前,使用以下命令在K8S集群中安装Rook准备入控制器:
#在master节点直接应用在线yaml文件
$ kubectl apply -f https://github.com/jetstack/cert-manager/releases/download/v1.7.1/cert-manager.yaml对所有需要安装ceph的work节点安装LVM2
$ yum install lvm2 -y
#检查是否安装成功
$ yum list installed | grep lvm2
lvm2.x86_64 8:2.03.14-9.el8 @anaconda
lvm2-libs.x86_64 8:2.03.14-9.el8 @anaconda在K8S集群中运行Ceph OSD的所有存储节点上都需要有这个包。虽然没有这个包Rook也能够成功创建Ceph OSD,但是当相应的节点(node)重启之后,其上运行的OSD pod将会启动失败。所以需要确保作为存储节点的操作系统上安装了LVM(从上面磁盘条件查验的结果中看到我们是有LVM卷的)。
Ceph需要一个带有RBD模块的Linux内核。大多数Linux发行版都有这个模块,但不是所有,你可以在K8S集群的存储节点上运行lsmod|grep rbd命令检测一下,如果该命令返回空,那说明当前系统内核没有加载RBD模块,可以使用以下命令尝试加载RBD模块:
# 将RBD模块加载命令放入开机加载项里
$ cat > /etc/sysconfig/modules/rbd.modules << EOF
#! /bin/bash
modprobe rbd
EOF
# 为上述为脚本添加执行权限
$ chmod +x /etc/sysconfig/modules/rbd.modules
# 执行上述脚本(如果返回'not found',你可能需要安装一个新的内核、或重新编译一个带有RBD模块的内核、或换一个带有RBD的Linux 发行版)
$ /bin/bash /etc/sysconfig/modules/rbd.modules
# 查看RBD模块是否加载成功
$ lsmod|grep rbd——————————- 以上为使用Rook在K8S集群部署Ceph存储的前提条件 ——————————-
3.2 使用Rook在K8S集群部署Ceph存储集群
使用Rook官方提供的示例部署组件清单(manifests)部署一个Ceph集群:
# 使用git将部署组件清单示例下载到本地(慢或无法接通的话自己想法办FQ)
$ git clone --single-branch --branch v1.12.8 https://github.com/rook/rook.git
# 进入到本地部署组件清单示例目录
$ cd rook/deploy/examples
# 执行以下命令将Rook和Ceph相关CRD资源和通用资源创建到K8S集群(其中psp.yaml是K8S 集群受Pod安全策略保护的情况下的可选资原文件)
$ kubectl create -f crds.yaml -f common.yaml -f filesystem.yaml -f psp.yaml
# kubernetes 1.25 版本中已经移除PodSecurityPolicy(PSP),可以不创建接下来部署Rook Operator组件,该组件为Rook与Kubernetes交互的组件,整个集群只需要一个副本,特别注意 Rook Operator 的配置在Ceph集群安装后不能修改,否则Rook会删除Ceph集群并重建,所以部署之前一定要做好规划,修改好operator.yaml 的相关配置:
修改rook/deploy/examples/operator.yaml文件中的以下内容:
# 修改镜像地址为华中科技大学和阿里云的(可以使用docker pull <url>验证一下,原来的地址很难下载)
ROOK_CSI_CEPH_IMAGE: "quay.mirrors.ustc.edu.cn/cephcsi/cephcsi:v3.7.2"
ROOK_CSI_REGISTRAR_IMAGE: "registry.aliyuncs.com/google_containers/csi-node-driver-registrar:v2.7.0"
ROOK_CSI_RESIZER_IMAGE: "registry.aliyuncs.com/google_containers/csi-resizer:v1.7.0"
ROOK_CSI_PROVISIONER_IMAGE: "registry.aliyuncs.com/google_containers/csi-provisioner:v3.4.0"
ROOK_CSI_SNAPSHOTTER_IMAGE: "registry.aliyuncs.com/google_containers/csi-snapshotter:v6.2.1"
ROOK_CSI_ATTACHER_IMAGE: "registry.aliyuncs.com/google_containers/csi-attacher:v4.1.0"
# 打开CephCSI 提供者的节点(node)亲和性(去掉前面的注释即可,会同时作用于CephFS和 RBD提供者,如果要分开这两者的调度,可以继续打开后面专用的节点亲和性)
CSI_PROVISIONER_NODE_AFFINITY: "role=storage-node; storage=rook-ceph"
# 如果CephFS和RBD提供者的调度亲各性要分开,则在上面的基础上继打开它们专用的开关(去 除下面两行前端的#即可)
# CSI_RBD_PROVISIONER_NODE_AFFINITY: "role=rbd-node"
# CSI_CEPHFS_PROVISIONER_NODE_AFFINITY: "role=cephfs-node"
# 打开CephCSI 插件的节点(node)亲和性(去掉前面的注释即可,会同时作用于CephFS和RBD 插件,如果要分开这两者的调度,可以继续打开后面专用的节点亲和性)
CSI_PLUGIN_NODE_AFFINITY: "role=storage-node; storage=rook-ceph"
# 如果CephFS和RBD提供者的调度亲各性要分开,则在上面的基础上继打开它们专用的开关(去除下面两行前端的#即可)
# CSI_RBD_PLUGIN_NODE_AFFINITY: "role=rbd-node"
# CSI_CEPHFS_PLUGIN_NODE_AFFINITY: "role=cephfs-node"
# rook-ceph-operator的Deployment中的容器镜像地址rook/ceph:v1.10.11 可以不用换,下载还是很快的!
# 生产环境一般还会打开裸设备自动发现守护进程(方便后期增加设备)
ROOK_ENABLE_DISCOVERY_DAEMON: "true"
# 同时开打发现代理的节点亲和性环境变量
- name: DISCOVER_AGENT_NODE_AFFINITY
value: "role=storage-node; storage=rook-ceph"修改完后,根据如上的节点标签亲和性设置,为三个工作节点打上对应的标签:
kubectl label nodes node01 node02 node03 role=storage-node
kubectl label nodes node01 node02 node03 storage=rook-ceph确认修改完成后,在master节点上执行以下命令进行Rook Ceph Operator的部署:
# 执行以下命令在K8S集群中部署Rook Ceph Operator(镜像拉取可能需要一定时间,耐心等待,可用后一条命令监控相关Pod部署情况)
$ kubectl create -f operator.yaml
# 使用以下命令监控Rook Ceph Operator相关Pod的部署情况(rook-ceph为默认Rook Ceph Operator部署命名空间)
$ watch kubectl get pods -n rook-ceph确保rook-ceph-operator相关Pod都运行正常的情况下,修改rook/deploy/examples/cluster.yaml文件中的以下内容:
# enable prometheus alerting for cluster
monitoring:
# requires Prometheus to be pre-installed
enabled: false #如果集群中没有安装prometheus的小伙伴不要开启!!
# To control where various services will be scheduled by kubernetes, use the placement configuration sections below.
# The example under 'all' would have all services scheduled on kubernetes nodes labeled with 'role=storage-node' and
# tolerate taints with a key of 'storage-node'.
placement:
all:
nodeAffinity: #打开节点亲和性调度和污点容忍
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: role
operator: In
values:
- storage-node
# podAffinity:
# podAntiAffinity:
# topologySpreadConstraints:
# tolerations:
# - key: storage-node
# operator: Exists
storage: # cluster level storage configuration and selection
useAllNodes: false
useAllDevices: false
#deviceFilter:
config:
# crushRoot: "custom-root" # specify a non-default root label for the CRUSH map
# metadataDevice: "md0" # specify a non-rotational storage so ceph-volume will use it as block db device of bluestore.
# databaseSizeMB: "1024" # uncomment if the disks are smaller than 100 GB
# journalSizeMB: "1024" # uncomment if the disks are 20 GB or smaller
# osdsPerDevice: "1" # this value can be overridden at the node or device level
# encryptedDevice: "true" # the default value for this option is "false"
# Individual nodes and their config can be specified as well, but 'useAllNodes' above must be set to false. Then, only the named
# nodes below will be used as storage resources. Each node's 'name' field should match their 'kubernetes.io/hostname' label.
nodes:
- name: "node01" # 注意,name 不能够配置为IP,而应该是标签 kubernetes.io/hostname 的内容
devices: # specific devices to use for storage can be specified for each node
- name: "sdb" # 将存储设置为我们三个工作节点新加的sdb裸盘,可以通过 lsblk查看磁盘信息
- name: "node02"
devices: # specific devices to use for storage can be specified for each node
- name: "sdb"
- name: "node03"
devices: # specific devices to use for storage can be specified for each node
- name: "sdb"
# - name: "nvme01" # multiple osds can be created on high performance devices
# config:
# osdsPerDevice: "5"
# - name: "/dev/disk/by-id/ata-ST4000DM004-XXXX" # devices can be specified using full udev paths
# config: # configuration can be specified at the node level which overrides the cluster level config
# - name: "172.17.4.301"
# deviceFilter: "^sd."
# when onlyApplyOSDPlacement is false, will merge both placement.All() and placement.osd
onlyApplyOSDPlacement: false先修改一下集群osd的资源限制,否则osd的内存使用率会无限增长(经验教训)
# 在186行处加入资源限制,建议内存设置4G以上,同时需要注意yaml文件的格式。
resources:
osd:
limits:
cpu: "2"
memory: "8000Mi"
requests:
cpu: "2"
memory: "8000Mi"部署等待(部署需要一定的时间,可用后一条命令监控)
# 确保工作节点打上对应标签,并且cluster文件修改好后,就可以使用cluster.yaml部署 Ceph存储集群了
$ kubectl create -f cluster.yaml
# 使用以下命令监控Ceph Cluster相关Pod的部署情况(rook-ceph为默认部署命名空间)
$ watch kubectl get pods -n rook-ceph查看最终Pod的状态
$ kubectl get pods -n rook-ceph
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-6k22v 2/2 Running 0 71m
csi-cephfsplugin-jxwph 2/2 Running 0 71m
csi-cephfsplugin-kkgzd 2/2 Running 0 71m
csi-cephfsplugin-provisioner-76bf9c9f6-62rcf 5/5 Running 0 71m
csi-cephfsplugin-provisioner-76bf9c9f6-9h2ws 5/5 Running 0 71m
csi-rbdplugin-4c6hq 2/2 Running 0 71m
csi-rbdplugin-provisioner-7f98cff8f8-ppffm 5/5 Running 0 71m
csi-rbdplugin-provisioner-7f98cff8f8-r9rrk 5/5 Running 0 71m
csi-rbdplugin-t27rt 2/2 Running 0 71m
csi-rbdplugin-xpjvj 2/2 Running 0 71m
rook-ceph-crashcollector-master01-7d9d95cff8-8g4wn 1/1 Running 0 93s
rook-ceph-crashcollector-master03-64c74ffd44-mzpd2 1/1 Running 0 94s
rook-ceph-crashcollector-node01-c99659fdb-4jdv6 1/1 Running 0 11m
rook-ceph-crashcollector-node02-59ccfb4dc9-tq2fc 1/1 Running 0 70m
rook-ceph-crashcollector-node03-74c554567b-ttnvg 1/1 Running 0 11m
rook-ceph-mds-myfs-a-6f76cfd6cf-v68n9 2/2 Running 0 94s
rook-ceph-mds-myfs-b-54f5dcbf9c-mdq4f 2/2 Running 0 93s
rook-ceph-mgr-a-8668657cb4-bpmlt 3/3 Running 0 70m
rook-ceph-mgr-b-dc9ccbd8f-k4bxd 3/3 Running 0 70m
rook-ceph-mon-a-856597bc9d-lh72x 2/2 Running 0 71m
rook-ceph-mon-b-677c59cd-w45bn 2/2 Running 0 71m
rook-ceph-mon-c-8bd76c874-7ccp5 2/2 Running 0 70m
rook-ceph-operator-578869b6b5-dnzhz 1/1 Running 0 11m
rook-ceph-osd-0-cc7675fd4-r28jh 2/2 Running 0 12m
rook-ceph-osd-1-5d89cfd65f-wmz7q 2/2 Running 0 11m
rook-ceph-osd-2-6746dc4fc-7r4jk 2/2 Running 0 11m
rook-ceph-osd-prepare-node01-m9n5w 0/1 Completed 0 11m
rook-ceph-osd-prepare-node02-42q8f 0/1 Completed 0 11m
rook-ceph-osd-prepare-node03-jvpz2 0/1 Completed 0 11m
rook-ceph-tools-757999d6c7-5jshs 1/1 Running 0 43m
rook-discover-bsjw4 1/1 Running 0 71m
rook-discover-g742p 1/1 Running 0 71m
rook-discover-gwdx5 1/1 Running 0 71m以上是所有组件 pod 完成后的状态,以 rook-ceph-osd-prepare 开头的 pod 用于自动感知集群新挂载硬盘,只不过我们前面手动指定了节点,所以这个不起作用。osd-0、osd-1、osd-2容器必须是存在且正常的,如果上述pod均正常运行成功,则视为集群安装成功。
如果部署成功一次后重新部署需要对磁盘重写,因为磁盘已经具有一个特定的 UUID,表示该磁盘已被使用,可以查看rook-ceph-osd-prepare的logs判断是否属于这种情况,使用如下命令解决
$ dd if=/dev/zero of="/dev/sdb" bs=1M count=100 oflag=direct,dsync # 每一台ceph节点都要执行
$ kubectl delete pod rook-ceph-operator-578869b6b5-dnzhz -n rook-ceph # 删除operator,使其重新检测
# 重新部署时需要删除/var/lib/rook
$ rm -rf /var/lib/rook3.3 开启prometheus
如果是使用自建prometheus,需要在config添加如下内容
- job_name: rook-ceph/rook-ceph-mgr/0
honor_labels: false
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- rook-ceph
scrape_interval: 5s
metrics_path: /metrics
relabel_configs:
- action: keep
source_labels:
- __meta_kubernetes_service_label_app
regex: rook-ceph-mgr
- action: keep
source_labels:
- __meta_kubernetes_service_label_rook_cluster
regex: rook-ceph
- action: keep
source_labels:
- __meta_kubernetes_endpoint_port_name
regex: http-metrics
- source_labels:
- __meta_kubernetes_endpoint_address_target_kind
- __meta_kubernetes_endpoint_address_target_name
separator: ;
regex: Node;(.*)
replacement: ${1}
target_label: node
- source_labels:
- __meta_kubernetes_endpoint_address_target_kind
- __meta_kubernetes_endpoint_address_target_name
separator: ;
regex: Pod;(.*)
replacement: ${1}
target_label: pod
- source_labels:
- __meta_kubernetes_namespace
target_label: namespace
- source_labels:
- __meta_kubernetes_service_name
target_label: service
- source_labels:
- __meta_kubernetes_pod_name
target_label: pod
- source_labels:
- __meta_kubernetes_service_name
target_label: job
replacement: ${1}
- target_label: endpoint
replacement: http-metrics4、安装 ceph 扩展
4.1 部署ceph dashboard
Ceph Dashboard 是一个内置的基于 Web 的管理和监视应用程序,它是开源 Ceph 发行版的一部分。通过 Dashboard 可以获取 Ceph 集群的各种基本状态信息。
$ cd rook/deploy/examples
$ kubectl apply -f dashboard-external-https.yaml创建NodePort类型就可以被外部访问了
$ kubectl get svc -n rook-ceph|grep dashboard
rook-ceph-mgr-dashboard ClusterIP 109.233.40.229 <none> 8443/TCP 8m28s
rook-ceph-mgr-dashboard-external-https NodePort 109.233.34.181 <none> 8443:32234/TCP 29s浏览器访问(master1-ip换成自己的集群ip):https://master-ip:32234/ (访问地址,注意是https,http会访问不成功)
Rook 创建了一个默认的用户 admin,并在运行 Rook 的命名空间中生成了一个名为rook-ceph-dashboard-admin-password的 Secret,要获取密码,可以运行以下命令:
$ kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}"|base64 --decode && echo
4.2 部署Ceph工具
Rook 工具箱是一个包含用于 Rook 调试和测试的常用工具的容器
$ cd rook/deploy/examples
$ kubectl apply -f toolbox.yaml -n rook-ceph待容器Running后,即可执行相关命令:
$ kubectl exec -it `kubectl get pods -n rook-ceph|grep rook-ceph-tools|awk '{print $1}'` -n rook-ceph -- bash
[rook@rook-ceph-tools-775f4f4468-dcg4x /]$ ceph -s
cluster:
id: b79e201e-5843-4dd1-83bc-86c54c16dfbc
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 67m)
mgr: a(active, since 7m), standbys: b
osd: 3 osds: 3 up (since 7m), 3 in (since 33m)
data:
pools: 1 pools, 1 pgs
objects: 2 objects, 449 KiB
usage: 63 MiB used, 600 GiB / 600 GiB avail
pgs: 1 active+clean
[rook@rook-ceph-tools-775f4f4468-dcg4x /]$ ceph osd status
ID HOST USED AVAIL WR OPS WR DATA RD OPS RD DATA STATE
0 node02 21.1M 199G 0 0 0 0 exists,up
1 node01 21.0M 199G 0 0 0 0 exists,up
2 node03 20.9M 199G 0 0 0 0 exists,up总结
至此通过Rook的这种方式成功的在K8S集群中部署了ceph服务,这种方式可以直接在生产环境使用。同时也可以看到使用Rook安装Ceph还是很简单的,只需要执行对应的yaml文件即可。
- 线上环境如有公有云不建议自己搭建CEPH集群;
- 部署搭建只是第一步,后续的优化及维护是重点,如没有相关经验不推荐直接线上使用;
- 数据永远是公司最宝贵的资源之一,一定要能扛起敬畏数据的责任;
5、基于RBD/CephFS的StorageClass
5.1 部署 RBD StorageClass
Ceph 可以同时提供对象存储 RADOSGW、块存储 RBD、文件系统存储 Ceph FS。
RBD 即 RADOS Block Device 的简称,RBD 块存储是最稳定且最常用的存储类型。
RBD 块设备类似磁盘可以被挂载。
RBD 块设备具有快照、多副本、克隆和一致性等特性,数据以条带化的方式存储在 Ceph 集群的多个 OSD 中。注意: RBD只支持ReadWriteOnce存储类型!
1、创建 StorageClass
$ cd rook/deploy/examples/csi/rbd
$ kubectl apply -f storageclass.yaml2、校验pool安装情况
$ kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') -- bash
[root@rook-ceph-tools-775f4f4468-dcg4x /]# ceph osd lspools
1 device_health_metrics
2 replicapool3、查看StorageClass
$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate true 43s4、将Ceph设置为默认存储卷
$ kubectl patch storageclass rook-ceph-block -p '{"metadata":{"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'修改完成后再查看StorageClass状态(有个default标识)
$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
rook-ceph-block(default) rook-ceph.rbd.csi.ceph.com Delete Immediate true 43s5、测试验证
创建pvc指定 storageClassName 为 rook-ceph-block
[root@master code]# cat rbd-pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-mysql-data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
storageClassName: rook-ceph-block5.2 部署 CephFS StorageClass
CephFS 允许用户挂载一个兼容posix的共享目录到多个主机,该存储和NFS共享存储以及CIFS共享目录相似;
1、创建 StorageClass
$ cd rook/deploy/examples/csi/cephfs
$ kubectl apply -f storageclass.yaml2、查看StorageClass
$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate true 12m
rook-cephfs rook-ceph.rbd.csi.ceph.com Delete Immediate true 57scephfs使用和rbd同样指定storageClassName的值便可,须要注意的是rbd只支持 ReadWriteOnce,cephfs能够支持ReadWriteMany 。
3、测试验证
$ cat cephfs-pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: redis-data-pvc
spec:
accessModes:
#- ReadWriteOnce
- ReadWriteMany
resources:
requests:
storage: 2Gi
storageClassName: rook-cephfs建立一个pod来使用pvc做存储并验证持久化效果(如果不是所有节点加入了ceph集群,需要添加节点选择器,在运行csi的节点上才可以正常挂载)
$ cat test-cephfs-pod.yml
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis:4-alpine
ports:
- containerPort: 6379
name: redisport
volumeMounts:
- mountPath: /data
name: redis-pvc
nodeSelector:
role: storage-node
volumes:
- name: redis-pvc
persistentVolumeClaim:
claimName: redis-data-pvc$ kubectl exec -it redis -- sh
/data #
/data # ls
/data # redis-cli
127.0.0.1:6379> set mykey "hello world"
OK
127.0.0.1:6379> get mykey
"hello world"
127.0.0.1:6379> BGSAVE
Background saving started
127.0.0.1:6379> exit
/data # ls
dump.rdb
# 删除pod
$ kubectl delete -f test-cephfs-pod.yml pod "redis" deleted
# 再次创建pod
$ kubectl apply -f test-cephfs-pod.yml pod/redis created
# 验证数据持久化
$ kubectl exec -it redis -- sh
/data #
/data # redis-cli 127.0.0.1:6379> get mykey
"hello world"6、使用场景
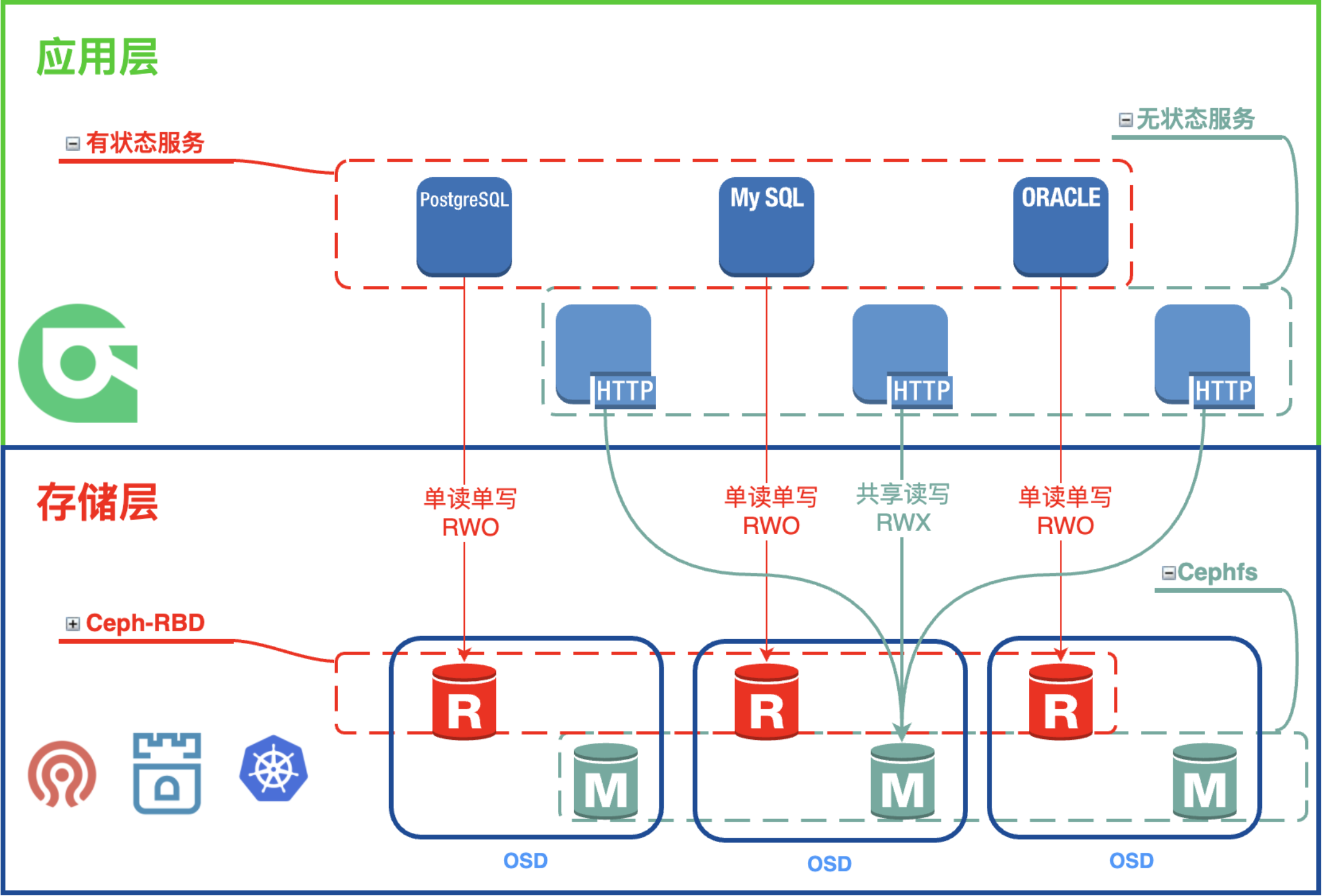
Cephfs:
优点:
- 1、读取延迟低,I/O带宽表现良好,尤其是较大一些的文件;
- 2、灵活度高,支持k8s的所有接入模式;
- 3、支持ReadWriteMany ;
缺点:
- cephfs的小文件读写性能一般,且写入延迟偏高;
适用场景:
- 适用于要求灵活度高(支持k8s多节点挂载特性);
- 对I/O延迟不甚敏感的文件读写操作或非海量的小文件存储支持。例如:常用的 应用/ 中间件 挂载存储后端;
Ceph RBD:
优点:
- 1、I/O带宽表现良好;
- 2、读写延迟都很低;
- 3、支持镜像快照,镜像转储;
缺点:
- 不支持多节点挂载(只支持ReadWriteOnce);
适用场景:
- 对I/O带宽和延迟要求都较高,没有多个节点同时读写数据需求的应用。例如: 数据库。
